1. Objectifs
L’objectif de cet article est de citer les best practices à suivre lors de la préparation d’un serveur Windows destiné à faire tourner le SGBD SQL Server, et lors de l’installation de ce SGBD.
2. Périmètre
Tous les serveurs SQL Server toutes versions.
3. Prérequis et meilleures pratiques pour l’Installation SQL Server
Avant toute installation d’un moteur de base de données SQL Server, il faut savoir :
- Sur quel système d’exploitation va tourner ce moteur (OS, Version, Edition, …)
- Les caractéristiques des serveurs (CPU, RAM, …)
- Quel mode d’installation (Standalone, cluster, …)
- S’il s’agit d’un cluster, quel mode de cluster (Failover Clustering ou Always On)
- Tous les composants à installer (Database Engine, replication, SSIS, SSAS, …)
- S’il s’agit de SSAS, quel mode de serveur à installer
- Instance par défaut ou nommée
- Les prérequis des applications qui vont utiliser le serveur SQL
- Collation
3.1 Prérequis et meilleures pratiques pour l’installation SQL Server (Standalone)
- Les comptes AD avec lesquels les composants SQL vont s’exécuter
- Tous les disques utilisés par SQL (Binaire, Backup, Data, Log, tempdb) soient alignés sur 64K et séparation des disques data, log, … si possible.
Par exemple :- C:\ Pour Windows
- S:\ Pour les binaires SQL Server
- B:\ Pour les backups des bases SQL Server
- D:\ Pour les fichiers Data des bases de données utilisateurs
- L:\ Pour les fichiers Log des bases de données utilisateurs
- T:\ Pour les fichiers de la base de données système TempDB
- Un compte Admin Local sur les serveurs à installer
- Idéalement, les instances de SQL Server devraient tourner sur un serveur dédié (physique ou virtuel) et sans qu’aucun autre logiciel ne fonctionne sur la machine
- Eviter l’exécution de multiples instances sur un même serveur (à moins d’avoir une bonne raison de le faire)
- Les services SQL Server non utilisés doivent être désactivés ou désinstallés
- Ne jamais utiliser le compte SA, et il faut le désactiver, de même pour le compte NT AUTHORITY SYSTEM, il faut privilégier l’authentification Windows
- Privilégier l’utilisation d’un compte de domaine qui est membre du rôle SysAdmin
- Allouer un espace suffisant aux fichiers MDF et LDF nouvellement créés, cela minimisera les événements AutoGrowth
- Donner une taille correcte à TempDB, cela évitera les événements AutoGrowth, et fixer l’AutoGrowth à une taille fixe plutôt que les 10% par défaut, cela minimisera les événements AutoGrowth
- Sur un serveur à forte activité, considérer de séparer la TempDB dans plusieurs fichiers physiques et si possible utiliser des devices sql différents (le nombre de fichiers répond à la formule : (espace disque – 10%) / (Nbre_CPU +1) avec un maximum de 8 fichiers.
3.2 Prérequis et meilleures pratiques pour l’installation SQL Server (Cluster)
3.2.1 Prérequis Cluster
- Selon le type de quorum choisi, un file Share qui va prendre le rôle de quorum
- Des disques alignés sur 64 K et partagés par tous les nœuds participants au cluster
- Un compte Admin Local sur les nœuds du cluster et admin de domaine
- Des adresses IP avec DNS pour le cluster
- Des adresses IP avec DNS pour le listener s’il s’agit de Always On
3.2.2 Prérequis SQL
- Même prérequis pour une installation Standalone
3.3 Maintenance de la base de données
3.3.1 Reorganize index or Rebuild Index
Lorsqu’un index est fragmenté de telle façon que la fragmentation nuit aux performances des requêtes, il existe trois possibilités de réduction de la fragmentation :
- Recréer les index
- Réorganiser les index
- Reconstruire les index
| Valeur avg_fragmentation_in_percent | Instruction corrective |
| > 10 % et < = 30 % | ALTER INDEX REORGANIZE |
| > 30% | ALTER INDEX REBUILD WITH (ONLINE = ON)* |
3.3.2 Update Statistics
L’optimiseur de requête est la partie de SQL Server qui détermine la façon dont une requête doit être exécutée, plus précisément quelles tables et index utiliser et quelles opérations réaliser sur ceux-ci pour obtenir les résultats : c’est ce qu’on appelle un plan de requête. Certaines des entrées les plus importantes de ce processus de prise de décision sont des statistiques qui décrivent la distribution des valeurs de données pour les colonnes d’une table ou d’un index. Évidemment, les statistiques doivent être précises et à jour pour être utiles à l’optimiseur de requête.
- Analysez les index et déterminez ceux qui doivent être traités et comment effectuer la suppression de la fragmentation
- Pour tous les index qui n’ont pas été reconstruits, mettez les statistiques à jour
- Mettez les statistiques à jour pour toutes les colonnes non indexées
3.3.3 Check database integrity
Afin de surveiller et d’assurer l’intégrité des données, il faut exécuter régulièrement DBCC CHECKDB sur les bases de données pour vérifier l’intégrité logique et physique de tous les objets des bases de données et éviter les pertes de données.
Si cette commande produit un résultat, c’est que DBCC a trouvé des corruptions dans la base de données, et c’est là qu’interviennent les sauvegardes.
3.3.4 Backup databases
La création de sauvegardes SQL Server a pour objectif de permettre la récupération d’une base de données endommagée. Toutefois, les sauvegardes et restaurations de données doivent être adaptées à un environnement particulier. Pour qu’elles soient efficaces, les sauvegardes et restaurations aux fins de récupération doivent par conséquent faire l’objet d’une stratégie. Une stratégie de sauvegarde et de restauration bien conçue doit maximiser la disponibilité des données et minimiser la perte de données, en prenant en compte les besoins spécifiques de votre entreprise.
Selon le RPO et le RTO d’un environnement et une base de données particulière, on peut concevoir une stratégie de backup, par exemple :
RTO : Recovery Time Objective
RPO : Recovery Point Objective

La planification des sauvegardes est la suivante :
- 1 Backup FULL par semaine (lundi soir)
- 1 Backup DIFF par jour (sauf le lundi)
- LOG Backups :
- Pour les serveurs non production
- Pas Backup LOG
- Pour les serveurs de production.
- Backup LOG chaque 2 heures
- Pour les serveurs non production
3.3.4.1 Mode de récupération
Suivant les pré-requis de l’éditeur et la criticité des données, la base de données peut être en mode de récupération :
SIMPLE
- Pas de sauvegarde des journaux de transactions.
- Dans ce mode de récupération, aucune instruction T-SQL n’est stockée dans les journaux de transactions.
- Les journaux de transactions occupent un volume très faible.
- Le processus de restauration est rapide.
- Gestion des journaux de transactions automatique par le moteur du SGBD.
- En cas de crash, la restauration peut se faire à l’aide la dernière sauvegarde full.
- Perte de toutes les nouvelles données et modifications qui ont eu lieu entre la dernière sauvegarde et le crash.
BULK
- Sauvegarde des journaux de transactions.
- Dans ce mode de récupération, seules les instructions T-SQL sont stockées dans les journaux de transactions.
- Les journaux de transactions occupent un volume faible.
- Le processus de restauration est lent.
- Gestion des journaux de transactions par le DBA.
- En cas de crash, la restauration peut se faire à l’aide de la dernière sauvegarde FULL et de tous les journaux de transactions sauvegardés.
- Pas de perte de données.
FULL
- Sauvegarde des journaux de transactions
- Dans ce mode de récupération, les instructions T-SQL ainsi que les pages sont stockées dans les journaux de transactions.
- Les journaux de transactions occupent un volume important.
- Le processus de restauration est lent.
- Gestion des journaux de transactions par le DBA.
- En cas de crash, la restauration peut se faire à l’aide de la dernière sauvegarde FULL et de tous les journaux de transactions sauvegardés.
- Pas de perte de données.
3.3.4.2 Sauvegarde de la base de données SQL
Trois Types de sauvegardes existent :
- Full
- Differential
- Transaction Log
3.3.5 Patcher SQL Server
Patcher les instances SQL Server est une étape très importante dans le cycle de vie de ces dernières, c’est pour cela qu’il faut accorder une attention particulière aux patching et le suivi de tous les Service Packs, Security Patches et cumulative Updates.
Une fois qu’un Service Pack a été publié, vous avez 1 an pour appliquer ce Service Pack afin de rester à un niveau supporté.
Les mises à jour cumulatives sont régulièrement publiées pour SQL Server et ces mises à jour incluent des corrections de bug et des améliorations pour SQL Server.
Les correctifs de sécurité sont des correctifs supplémentaires qui répondent à des problèmes de sécurité spécifiques dans SQL Server et doivent être appliqués dès leur publication. Puisque les CU incluent toutes les mises à jour depuis le dernier Service Pack, il vous suffit d’appliquer la dernière CU qui inclurait toute mise à jour de sécurité précédente.
Actuellement, et pour que notre instance soit supportée par Microsoft, il faut que toutes nos instances soient dans la liste ci-dessous :
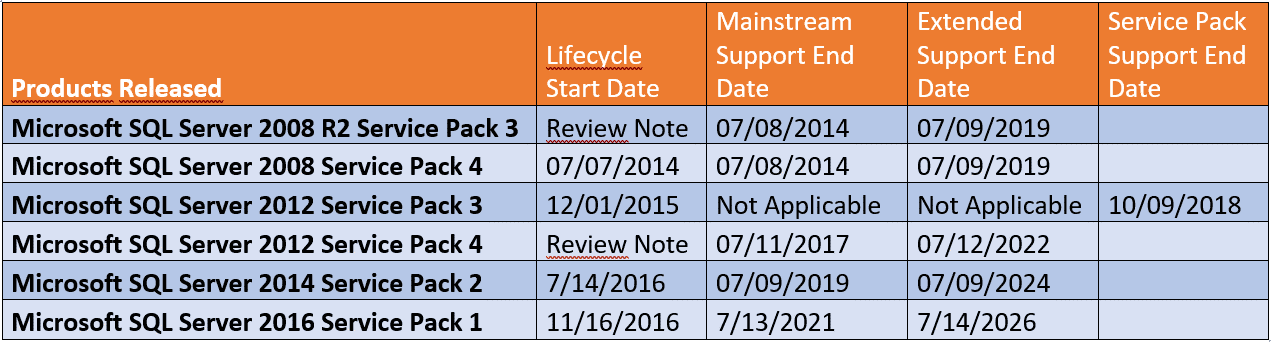
3.3.5.1 Patcher une instance en mode standalone
Si vous procédez à une mise à niveau de moteur de base de données, passez en revue le plan de mise à niveau du moteur de base de données, puis effectuez les tâches suivantes, en fonction de votre environnement :
- Sauvegardez tous les fichiers de base de données SQL Server de l’instance à mettre à niveau, afin de pouvoir les restaurer, si besoin.
- Exécutez les commandes DBCC CHECKDB appropriées sur les bases de données à mettre à niveau afin de vérifier leur cohérence.
- Estimez l’espace disque requis pour mettre à niveau les composants SQL Server ainsi que les bases de données utilisateur.
- Vérifiez que les bases de données système SQL Server (master, model, msdb et tempdb) sont configurées pour s’accroître automatiquement et vérifiez qu’elles disposent pour cela d’un espace disque suffisant.
- Lors de la mise à niveau des instances de SQL Server où l’Agent SQL Server qui est inscrit dans les relations MSX/TSX, mettez à niveau les serveurs cibles avant de mettre à niveau les serveurs maîtres. Si vous mettez à niveau les serveurs maîtres avant les serveurs cibles, l’Agent SQL Server ne sera pas en mesure de se connecter aux instances principales de SQL Server.
- Quittez toutes les applications, y compris tous les services ayant des dépendances SQL Server. La mise à niveau peut échouer si les applications locales sont connectées à l’instance en cours de mise à niveau.
- Assurez-vous que la réplication est arrêtée si elle existe.
3.3.5.2 Patcher une instance en mode cluster
Patcher un cluster est légèrement plus compliqué et le processus est différent pour SQL 2005 que pour les versions ultérieures à SQL 2005. Avec SQL Server 2005, le patch est appliqué au nœud actif du cluster et c’est le patch qui va dispatcher à tous les nœuds passifs et appliquera les fichiers patch à distance. Cela peut être la partie la plus problématique du processus et heureusement, cela a été supprimé dans SQL 2008.
A l’introduction de SQL Server 2008, tout processus d’installation à distance est supprimé. Cela s’applique également au processus de correction, ce qui nous est très utile dans le cadre d’un processus de correction, car cela signifie que nous pouvons maintenir la disponibilité du service pendant la correction. Avec un cluster SQL 2008 et plus, nous corrigeons toujours le nœud passif plutôt que le nœud actif. La correction des nœuds passifs signifie que SQL Server est disponible sur le nœud actif et que les clients peuvent donc continuer à utiliser le système.
3.3.5.3 Prise en charge de la mise à niveau SQL Server
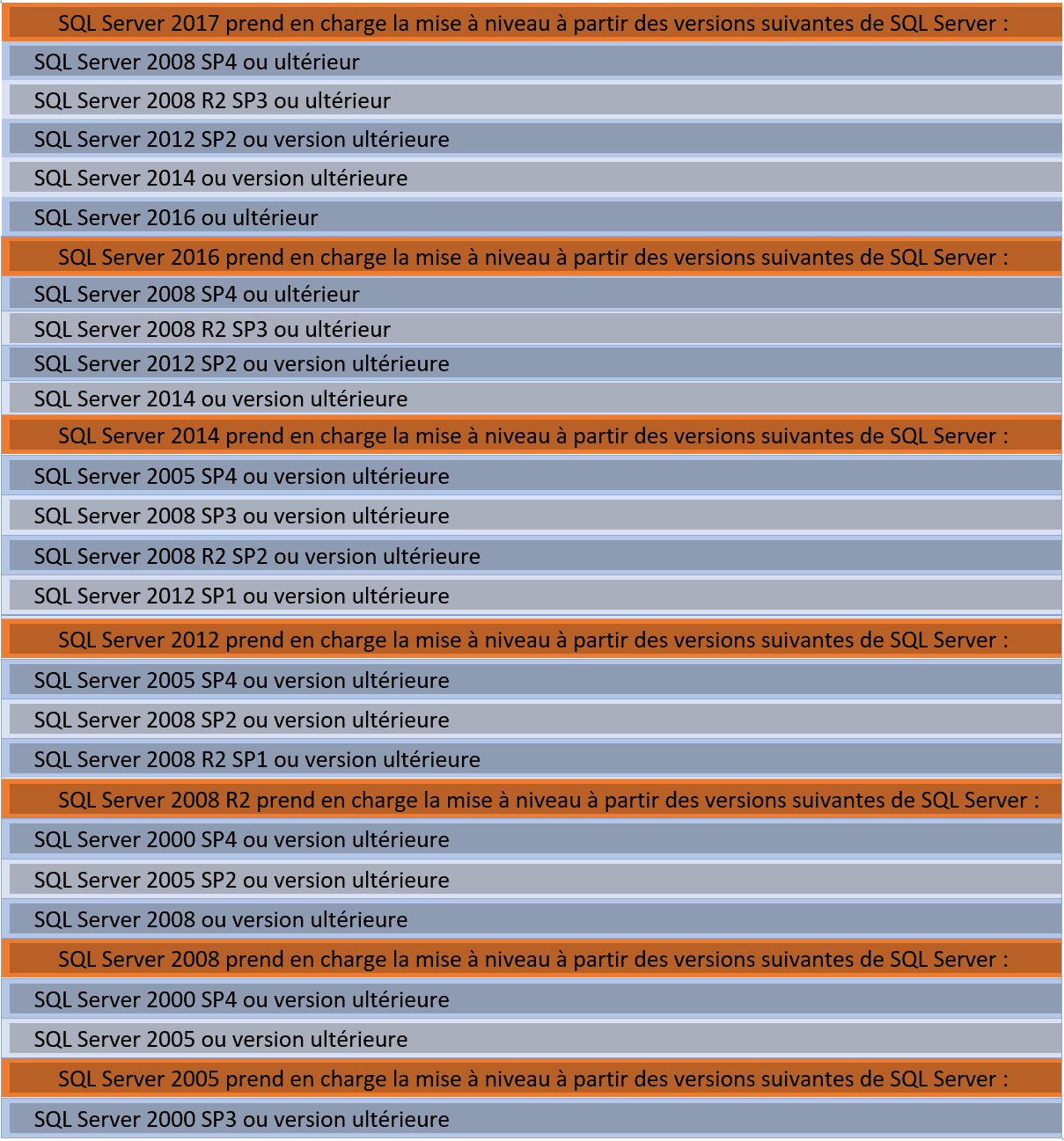
3.4 Exclusion antivirus
Lorsque vous configurez les paramètres de votre logiciel antivirus, assurez-vous que vous excluez les fichiers ou les répertoires (le cas échéant) suivant de l’analyse antivirus. Cela améliore les performances des fichiers et de s’assurer que les fichiers ne sont pas verrouillés lorsque le service SQL Server doit les utiliser. Toutefois, si ces fichiers sont infectés, votre logiciel antivirus ne peut pas détecter l’infection.
3.4.1 SQL Server Data Files
Ces fichiers contiennent les données dans les bases de données SQL server et ont généralement les extensions suivantes :
- .mdf – Primary Data filegroups.
- .ndf – Secondary Data filegroups.
- .ldf – Transaction Log filegroups.
3.4.2 SQL Server Backup Files
Ces fichiers contiennent les sauvegardes de bases de données SQL Server et ont généralement les extensions suivantes:
- .bak – Database backup files.
- .trn – Transaction Log backup files.
3.4.3 Full-Text Catalog Files
Un catalogue de texte intégral est un objet virtuel qui n’appartient à aucun groupe de fichiers; c’est un concept logique qui renvoie à un groupe d’index de recherche en texte intégral.
Le fichier FTDATA situé dans :
- Instance par défaut : Program Files\Microsoft SQL Server\MSSQL\FTDATA
- Une instance nommée : Program Files\Microsoft SQL Server\MSSQL$instancename\FTDATA
3.4.4 Analysis Services Data
Le répertoire qui contient toutes les données d’Analysis Services est spécifié par la propriété DataDir de l’instance de Analysis Services.
Par défaut, le chemin d’accès de ce répertoire est : Program Files\Microsoft SQL Server\MSSQL.X\OLAP\Data.
3.4.5 The directory that holds Analysis Services log files
L’emplacement du fichier journal est l’emplacement qui est spécifié par la propriété LogDir.
Par défaut, ce répertoire est : C:\Program Files\Microsoft SQL Server\MSSQL.X\OLAP\Log.
3.4.6 Analysis Services backup files
Par défaut, dans Analysis Services 2005 et les versions ultérieures, l’emplacement du fichier de sauvegarde est l’emplacement qui est spécifié par la propriété Répertoire_Sauvegarde.
Par défaut, ce répertoire est : C:\Program Files\Microsoft SQL Server\MSSQL.X\OLAP\Backup.
Vous pouvez modifier ce répertoire dans les propriétés de l’instance de Analysis Services. Toute commande de sauvegarde peut pointer vers un autre emplacement. Ou, les fichiers de sauvegarde peuvent être copiées ailleurs.
3.4.7 The directory that holds Reporting Services temporary files and Logs
Le répertoire contenant les fichiers temporaires de Reporting Services et les journaux (RSTempFiles et fichiers journaux).
3.4.8 Filestream data files
FILESTREAM permet aux applications SQL Server de stocker des données non structurées, telles que des documents et des images, dans le système de fichiers. Les applications peuvent tirer parti des API de diffusion et des performances du système de fichiers, c’est ce dossier qu’il faut exclure de l’analyse antivirus.
3.4.9 Processes to exclude from virus scanning
En plus d’exclure les fichiers SQL Server et Analysis Services, il est recommandé d’exclure la liste suivante des processus des analyses antivirus :
SQL Server 2012
- %ProgramFiles%\Microsoft SQL Server\MSSQL11.<Instance Name>\MSSQL\Binn\SQLServr.exe
- %ProgramFiles%\Microsoft SQL Server\MSRS11.<Instance Name>\Reporting Services\ReportServer\Bin\ReportingServicesService.exe
- %ProgramFiles%\Microsoft SQL Server\MSAS11.<Instance Name>\OLAP\Bin\MSMDSrv.exe
3.4.10 Special Considerations For SQL Server Clustering
Vous pouvez exécuter un logiciel antivirus sur un cluster SQL Server. Toutefois, il se peut que vous deviez vous assurer que le logiciel antivirus est sur une version prenant en charge les clusters. Contactez votre fournisseur d’antivirus sur les versions compatibles avec les clusters et l’interopérabilité.
Si vous exécutez un logiciel antivirus sur un cluster, assurez-vous que ces emplacements également exclure de l’analyse antivirus :
- Q:\ (Le lecteur quorum)
- C:\Windows\Cluster

4 réflexions sur “Microsoft SQL Server Best Practices”
Un article très intéressant pour commencer avec la configuration SQL server. Un grand merci à Samir pour ce travail et ce partage de connaissance.
Au plaisir
Merci à vous !
Pour cette belle expérience partagée.
Merci pour cet article Samir et merci Olivier pour ce commentaire 🙂
Voila une belle synthèse des best practices SQL Server ! Merci Samir ! Je me permet quelques compléments (non exhaustifs):
En ce qui concerne la partie système, il faut également porter une attention particulière aux options d’alimentation (PowerOption) trop souvent configurées à « balanced » au lieu de « High performance », recommandé pour SQL Server.
En ce qui concerne le moteur SQL, j’ajouterai:
– activation du traceflag 2371 pour la gestion des stats sur les version antérieure à 2016 (comportement par défaut depuis cette version)
– activation des traceflag 1117 et 1118 pour la gestion des Tempdb multi-fichiers, sur les versions antérieures à 2016, (activés par défaut depuis 2016)
– activer IFI (Instant File Initialisation) pour accélérer les allocations d’espace pour les fichiers de DATA
– Activer l’option ‘remote admin connections’ qui permettra d’utiliser la DAC à distance en cas de problème
– Activer l’option WITH CHECKSUM lors des sauvegardes,
– Activer la compression des sauvegardes (depuis 2008) : gain d’espace, mais surtaout de temps de backup ET de restauration
– les recommandations concernant les seuils et les opérations de DEFRAG / REBUILD datent de SQL 2000… A l’époque, les disques n’offraient pas les mêmes performances qu’aujourd’hui, et les espaces mémoire étaient largement inférieurs aux systèmes actuels. Il faut en finir avec les jobs planifiés de manière hebdomadaire et qui font de la défragmentation massive. Ces jobs incidentogène, provoquent des saturations IO des baies sous jacentes, et remplisse les TLOG avec bien souvent des erreurs liées à des TLOG full (9002). J’invite à lire l’article de l’excellentissime Brent Ozar sur ce sujet, qui date de 2012 et est encore plus vrai aujourd’hui 🙂 : https://www.brentozar.com/archive/2012/08/sql-server-index-fragmentation/. Le point d’entrée en ce qui concerne la fragmentation est de comprendre pourquoi elle survient, quel est sont impact et est-ce que les performance sont vraiment impactées …
Enfin, sur la partie SSAS, le plus important est de sauvegarder les fichiers master.vmp et msmdsrv.ini, indispensable au redémarrage de l’instance et à sa configuration. Les bases sont rarement sauvegardées, on préférera généralement redéployer le schéma et lancer un process FULL…
O.
Les commentaires sont fermés.