

Détecter les lignes migrées avec AWR
 Le 06/05/2020
Le 06/05/2020Données / Sécurité
Oracle
 8 minutes de lecture
8 minutes de lecturePartage





Détecter les lignes migrées avec AWR
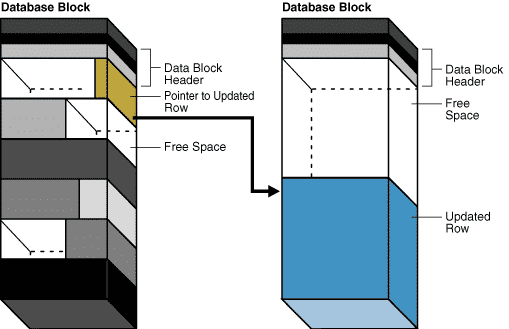
La présence de lignes migrées dans une table peut avoir des conséquences importantes sur les performances lors des accès en lecture, en particulier dans le cas de requêtes parallèles réalisant des FULL SCAN de grosses tables.
Normalement, un full scan d'une table ou d'une partition se traduit par ces évènements d'attente (principalement) :- db_file_scattered_read : lecture dans le buffer cache
- direct_path_read : lecture dans la PGA du process client dans le cas du parallel query
analyze table MA_TABLE.. list chained rows into tab_chained_rows;
Sur un exemple, voici les conséquences de la présence de nombreuses lignes migrées en termes de perte de performance, sur un SELECT parallèle impliquant 2 tables en FULL SCAN et dont voici un extrait du plan d'exécution : Les 2 tables FAIT1 et FAIT2 sont parcourues en FULL SCAN par des process parallèles (PX BLOCK ITERATOR).
Les 2 tables FAIT1 et FAIT2 sont parcourues en FULL SCAN par des process parallèles (PX BLOCK ITERATOR).
 On observe dans cette capture de Cloud Control d'une exécution d'un ordre SQL exécuté avec un parallélisme de 8, que les attentes IO représentent 41% (26 mn) du database time total (1,1h).
On observe dans cette capture de Cloud Control d'une exécution d'un ordre SQL exécuté avec un parallélisme de 8, que les attentes IO représentent 41% (26 mn) du database time total (1,1h).
 Sur cette autre capture de l'activité de la requête, on voit que l'évènement d'attente IO "db_file_sequential_read" représente 89% de la classe d'attente User IO, c'est à dire 89% de 26 minutes, soit 22 minutes sur le temps en base. Ce qui représente tout de même 2mn 45 sur les 8,3mn d'exécution, uniquement dues au surcroit de lecture des lignes migrées !
Cela vaut donc la peine de s'intéresser de plus près à la réduction de ce phénomène et pour cela essayer de le détecter au plus tôt.
Comment prévenir l'apparition de lignes migrées ?
Sur cette autre capture de l'activité de la requête, on voit que l'évènement d'attente IO "db_file_sequential_read" représente 89% de la classe d'attente User IO, c'est à dire 89% de 26 minutes, soit 22 minutes sur le temps en base. Ce qui représente tout de même 2mn 45 sur les 8,3mn d'exécution, uniquement dues au surcroit de lecture des lignes migrées !
Cela vaut donc la peine de s'intéresser de plus près à la réduction de ce phénomène et pour cela essayer de le détecter au plus tôt.
Comment prévenir l'apparition de lignes migrées ?
- En adaptant la valeur du PCTFREE à la taille des lignes et au volume de mises à jour de celles-ci
- En revoyant le mécanisme d'alimentation de la table, de manière à limiter les update suivant un insert
- En positionnant des valeurs par défaut aux champs non valorisés au 1er insert, lorsque c'est possible
- En limitant à moins de 255 le nombre de colonnes d'une table
- En déplaçant toutes les lignes dans de nouveaux blocs : ALTER TABLE...MOVE...
- En supprimant les lignes migrées (d'après leur rowid) et en les réinsérant individuellement après avoir appliqué les mesures ci-dessus permettant de limiter ou empêcher la création de ces lignes.
SELECT /*+ NO_MERGE(SRO) LEADING(SRO) USE_HASH(SRO O) */ SRO.module, SRO.action, O.owner, O.object_name, O.subobject_name, O.object_type, SRO.inst_id, SUM(SRO.Cnt_Obj) AS Cnt_Obj, MAX(ROUND(S.bytes / (1024 *1024),2)) AS Size_Mo, MAX(ST.num_rows) AS num_rows, MAX(ST.avg_row_len) AS avg_row_len, MAX(ST.last_analyzed) AS last_analyzed, LISTAGG(SRO.sql_id, ';') WITHIN GROUP (ORDER BY SRO.sql_id) AS List_SQL_ID FROM (SELECT SR.module, SR.action, SR.current_obj#, SR.inst_id, SR.sql_id, SUM(cnt_sample) AS Cnt_Obj FROM (SELECT NVL(ASH.qc_instance_id, ASH.instance_number) AS instance_number, NVL(ASH.qc_session_id, ASH.session_id) AS session_id, NVL(ASH.qc_session_serial#, ASH.session_serial#) AS session_serial#, ASH.instance_number AS inst_id, ASH.sql_id, ASH.sql_plan_hash_value, ASH.sql_exec_id, CAST(ASH.sample_time AS DATE) AS sample_time, ASH.sql_exec_start, ASH.current_obj#, ASH.module, ASH.action, COUNT(*) AS cnt_sample FROM dba_hist_active_sess_history ASH WHERE ASH.sample_time >= (SYSDATE - 10) AND ASH.sample_time <= SYSDATE AND ASH.session_state = 'WAITING' AND ASH.sql_plan_operation = 'TABLE ACCESS' AND ASH.sql_plan_options = 'FULL' AND ASH.event = 'db file sequential read' AND ASH.p1 > 0 GROUP BY NVL(ASH.qc_instance_id, ASH.instance_number), NVL(ASH.qc_session_id, ASH.session_id), NVL(ASH.qc_session_serial#, ASH.session_serial#), ASH.instance_number, ASH.sql_id, ASH.sql_plan_hash_value, ASH.sql_exec_id, CAST(ASH.sample_time AS DATE), ASH.sql_exec_start, ASH.current_obj#, ASH.module, ASH.action ) SR GROUP BY SR.module, SR.action, SR.current_obj#, SR.inst_id, SR.sql_id ) SRO JOIN dba_objects O ON (O.object_id = SRO.current_obj#) JOIN dba_segments S ON (S.owner = O.owner AND S.segment_name = O.object_name AND S.segment_type = O.object_type AND NVL(S.partition_name, 'X') = NVL(O.subobject_name, 'X')) JOIN dba_tab_statistics ST ON (ST.owner = S.owner AND ST.table_name = S.segment_name AND ST.object_type = DECODE(S.segment_type, 'TABLE PARTITION','PARTITION', 'TABLE SUBPARTITION','SUBPARTITION', S.segment_type) AND NVL(O.subobject_name,'X') = COALESCE(ST.subpartition_name, ST.partition_name, 'X')) GROUP BY SRO.module, SRO.action, O.owner, O.object_name, O.subobject_name, O.object_type, SRO.inst_id HAVING SUM(SRO.Cnt_Obj) >= 100 ORDER BY SRO.module, SRO.action, O.owner, O.object_name, O.subobject_name, O.object_type, SRO.inst_id;Cette requête permet donc de sélectionner les infos recherchées sur 10 jours d'historique AWR et 100 occurrences minimum de l'évènement avec les filtres repris ci-dessous :
WHERE ASH.sample_time >= (SYSDATE - 10) AND ASH.sample_time <= SYSDATE AND ASH.session_state = 'WAITING' AND ASH.sql_plan_operation = 'TABLE ACCESS' AND ASH.sql_plan_options = 'FULL' AND ASH.event = 'db file sequential read'... HAVING SUM(SRO.Cnt_Obj) >= 100 La même requête peut bien sûr être sélectionnée plusieurs fois si elle est exécutée plusieurs fois durant la période d'analyse. Ci-dessous un exemple d'exécution (adapté pour la lisibilité) :
MODULE ACTION OWNER OBJECT_NAME OBJECT_TYPE INST_ID CNT_OBJ TAILLE_MO NUM_ROWS AVG_ROW_LEN LAST_ANALYZED LIST_SQL_ID ALIM1 Sel1 DMT FAIT1 TABLE 1 360 30674 24593163 167 2020-02-10 22:07:32.0 51fgz39b14n5q ALIM2 Sel2 DMT FAIT2 TABLE 2 164 40471 345543121 220 2020-01-10 22:01:17.0 42fti59s27n5dOn voit que la table FAIT1 a fait l'objet de 360 occurrences de l'évènement "db_file_sequential_read" pendant le FULL SCAN exécuté par le sql_id "51fgz39b14n5q"du module ALIM1. On commencera donc par confirmer en premier lieu le nombre de lignes migrées de cette table avec l'ordre ANALYSE TABLE LIST CHAINED ROWS ainsi que la valeur de son PCTFREE au regard de la taille moyenne d'une ligne et on l'adaptera si besoin, ce qui reste l'action corrective la plus simple (pour les nouveaux blocs). Pour aller plus loin dans cette analyse, vous pouvez parcourir les articles ci-dessous :
- http://sateeshv-dbainfo.blogspot.com/2017/06/why-do-oracle-db-file-sequential-reads.html
- https://blogs.oracle.com/performancediagnosis/migrated-rows-and-pdml
- https://tanelpoder.com/2009/11/04/detect-chained-and-migrated-rows-in-oracle/
Partage
