

Comprendre et répartir les coûts d’un compte AWS
 Le 03/05/2021
Le 03/05/2021AWS
Cloud
 8 minutes de lecture
8 minutes de lectureSommaire
Sommaire
Partage





Comprendre et répartir les coûts d’un compte AWS
1- Introduction
Pour maîtriser les coûts d’un compte AWS, il est nécessaire de comprendre ces coûts. AWS mets à disposition deux services pour consulter les coûts : AWS COST EXPLORER et AWS BUDGET. Hélas, ces services sont très génériques, et ne mettent pas beaucoup d’information pour permettre aux gérants de comptes de comprendre les coûts. Et surtout ces services exposent exclusivement des données très techniques, avec des unités AWS. Parfois, les entreprises ont besoin de mapper ces coûts avec leurs divisions, pour être capable d'agréger les coûts aux différents niveaux de division. Dans ma mission chez un client, j’ai travaillé sur un projet consistant à mettre en place un processus de répartition des coûts AWS par différents niveaux de divisions, pour ses comptes AWS mutualisés. Cet article à pour but de partager mon expérience sur ce sujet.2- Architecture
Le service AWS COST EXPLORER permet de consulter les coûts d’un compte AWS. Pour plus de détail voir AWS COST EXPLORER DOCS. Les axes d’agrégation disponibles dans ce service :- L’unité du temps (année/mois/jour/heure)
- Le service (service AWS, exemple EC2, ATHENA, S3, …)
- Les tags des ressources (certains labels du type clé-valeur définie par les utilisateurs au niveau des ressources AWS)
- Et d’autres champs très techniques tels que la quantité d’usage, le type d’usage, l’identifier
- Trouver les bons tags pour la ressource
- Vérifier si la ressource a les bons tags
- Ajouter les bons tags si la ressource n’en possède pas
2.1 Processus de taggage automatique des ressources AWS
La solution idéale pour ce processus réaliser est d’utiliser une fonction AWS LAMBA. Les fonctions LAMBA dans AWS ont la particularité d’être déclenchées par plusieurs sources d’événement AWS. Cette fonction lambda doit écouter les événements de création des ressources AWS. Et à chaque événement elle doit :- Trouver les bons tags pour la ressource. Elle peut faire appel à une API interne pour récupérer les informations de l’utilisateur créateur de la ressource. Il faut noter que dans l’événement de création d’une ressource, il y a l’identité AWS de l’utilisateur créateur de la ressource.
- Vérifier si la ressource a les bons tags
- Ajoutre les bons tags si la ressource n’en possède pas en utilisant l’API AWS RESOURCE TAGGING
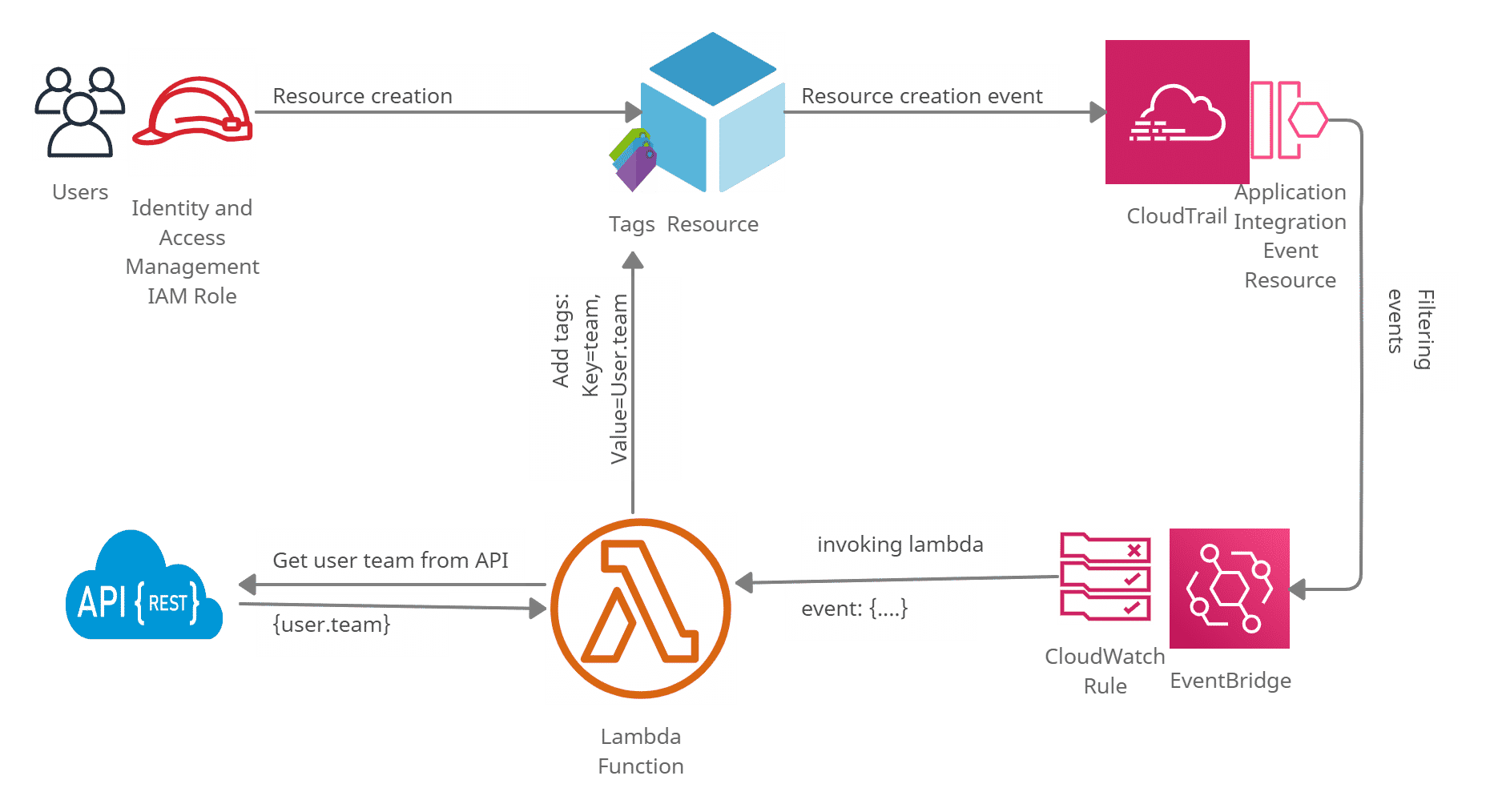 Cette fonction lambda permet d’assurer de taguer correctement les ressources AWS, ainsi que la répartition des coûts.
L’étape suivante est le reporting sur les données des coûts.
Cette fonction lambda permet d’assurer de taguer correctement les ressources AWS, ainsi que la répartition des coûts.
L’étape suivante est le reporting sur les données des coûts.
2.2- Processus de reporting des coûts AWS
Le service AWS COST REPORT expose des API pour requêter sur les données des coûts. Pour faire son propre report, il faut récupérer ces données. Une fonction Lambda peut faire la récupération journalière de ces données, agréger par jour par service et par tag équipe, pour les stocker dans un bucket S3. Et sur les fichiers S3 on peut exposer des tables dans le service Athena pour des requêtages avec SQL. A partir de ces tables Athena, on peut faire des reports avec les outils de reporting tel que PowerBI. Pour enrichir le report on peut utiliser des référentiels avec l’organigramme de l’entreprise.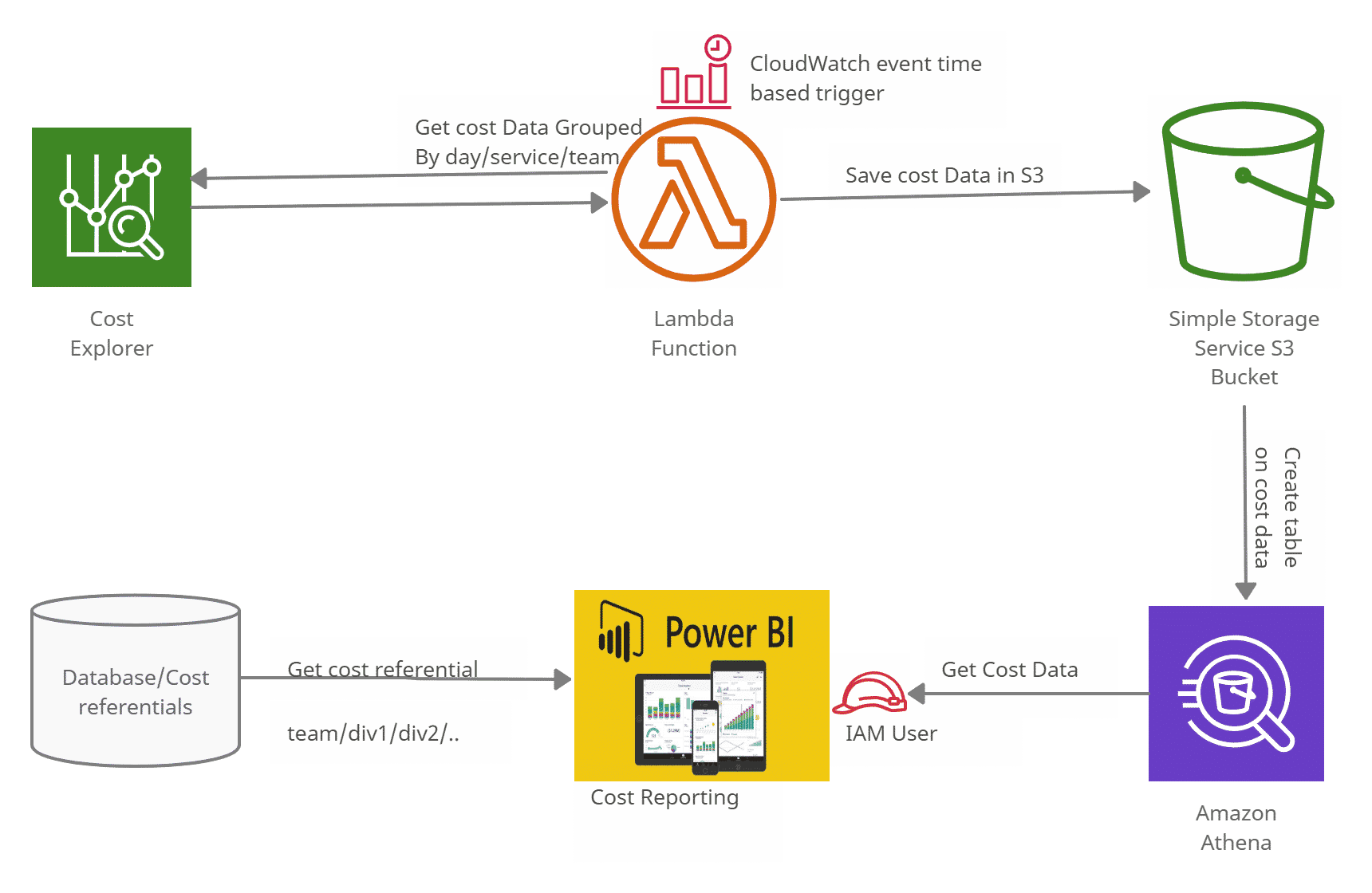
3- Implémentation de l'architecture
3.1- Processus de taggage automatique des ressources AWS
L’implémentation se fait dans la console AWS. Il faut créer les ressources nécessaires pour répondre à l’architecture précédente. Il faut :- Créer le rôle IAM de la fonction lambda du taggage
- La fonction lambda du taggage
- Les règles de filtrage des événements dans AWS EventBridges.
- L'identité du créateur de la ressource tels que les rôles IAM, les utilisateurs IAM, ...
- les tags passés lors de la création
- l'identité (ARN) ou le nom de la ressource
3.2- Processus de reporting des coûts AWS
La première étape est de récupérer les données pour le reporting. Il faut:- Créer un rôle IAM pour la fonction Lambda : ce rôle doit avoir les droits nécessaires pour faire appel à l'API AWS COST EXPLORER.
- Créer un bucket S3 pour stocker les données des coûts.
- Créer la fonction lambda. L'API AWS COST EXPLORER demande en entrée :
- Une durée (date début et date fin).
- Une mesure pour les coûts, il s'agit des différentes façons de consulter les coûts, tels que les coûts amortis, les coûts nets, les coûts pondérés. Pour plus de détails voir différents types de mesure des coûts AWS. Pour avoir une vision plus proche de la facturation, il faut utiliser les coûts amortis (AmortizedCost).
- Des axes d'agrégation. L'API supporte au maximum deux axes d'agrégation.
- Créer un déclencheur pour la fonction lambda du type crontab dans AWS CLOUDWATCH
- Une fois les données stockées dans un bucket S3, créer des tables dans Athena.
- Créer une identité IAM (IAM rôle, ou IAM user) ayant accès aux données pour l'outil de report. Pour avoir des accès permanents il faut créer un User IAM : en effet, les rôles IAM hors AWS donnent des accès temporaires.
Conclusion
L'architecture de la partition des coûts s'applique sur un compte AWS donné. Mais cette architecture est facilement réplicable dans d'autres comptes. Pour faciliter la réplication, on peut définir cette architecture avec AWS CloudFormation. Dans cette architecture, la partie, la plus complexe est le taggage des ressources. En effet, la fonction Lambda qui tague automatiquement les ressources, couvre la plus part des cas. Mais cette Lambda doit être monitorée pour intervenir en cas d'erreur.Partage
