

Chargement des données Météo depuis une API public ERA5 vers le Cloud AWS
 Le 02/04/2021
Le 02/04/2021AWS
Cloud
Non classé
S3
 5 minutes de lecture
5 minutes de lectureSommaire
Sommaire
Partage





Chargement des données Météo depuis une API public ERA5 vers le Cloud AWS
1- Introduction
Les données météorologiques sont très utiles dans plusieurs domaines de business. Il existe de nombreux fournisseurs, parmi eux, le centre météorologique Européen (ECMWF). Ce centre expose les données météorologiques du type Forecast à travers des API Rest publics. Cependant, ces API publiques sont très sollicitées, et fonctionnent avec un mécanisme de file d’attente. Le temps d’attente dans la file de l’API n’est pas négligeable, et peut atteindre une semaine. Pour rendre ces données hautement disponibles, il faut les charger dans un systèmes de stockage. J’ai travaillé sur une application qui charge ces données dans le lac de données d’AWS (s3) au cours d'une mission. Le but de cet article est de partager mon expérience.2- Architecture et développement de l'application
2.1. Données météorologiques & contraintes de l’API REST du centre météorologique Européen
Les données météorologiques ERA5 sont structurées en variables (Température, Vent, Pression, ..). Les variables sont définies à travers l’espace (longitude, latitude, altitude) et le temps (granularité heure). L’historique remonte à 1979. Les données sont publiées mois par mois, avec un retard de deux à trois mois. L’API REST possède des contraintes :- La taille des données retournées est limitée à 20 GB, donc la taille de la requête définissant le retour est limitée.
- Le nombre de requêtes simultanées est limité à 20 par compte utilisateur.
- Il n’y a pas d’estimation de temps d’attente.
2.2. Architecture de l'application
Le processus de chargement des données de l’API EST vers AWS S3, a été divisé en deux parties :- Une première partie pour le chargement de l’historique.
- Une deuxième partie pour chargement des nouvelles données une fois publiées (une fois par mois).
2.2.1. Le chargement des données historiques
Nous avons 32 variables météorologiques à charger. Nous avons réparti les variables en cinq lots de façon à récupérer le maximum de données par requête, et à minimiser le nombre de requêtes. Une fois les données récupérées, nous séparons les variables de façon à avoir un fichier par variable par mois par région définie par les météorologues. L’objectif de la répartition est de faciliter la recherche de ces données dans le lac de données (On parle de partitionnement de données). Nous chargeons les données de tous les points du globe pour être certain de couvrir les besoins des météorologues. Le processus se décompose en deux phases :- Une phase de téléchargement via à l’API et chargement dans le lac de données.
- Une phase de concassage du fichier téléchargé en plusieurs petits fichiers (par région, par niveau d’altitude, par mois, par variable) et chargement dans le lac des données.
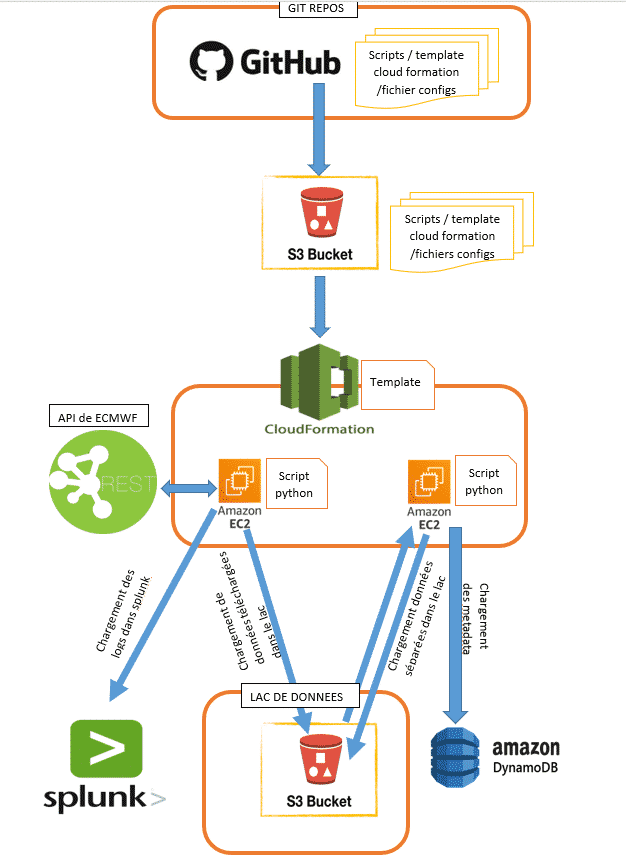 Nous avons un repos Git pour nos scripts et ainsi que les « templates cloudformation ».
Ces scripts et templates sont chargés manuellement dans un bucket S3 (Bucket Dev). Nous avons deux templates cloudformation :
Nous avons un repos Git pour nos scripts et ainsi que les « templates cloudformation ».
Ces scripts et templates sont chargés manuellement dans un bucket S3 (Bucket Dev). Nous avons deux templates cloudformation :
- Une template pour le provisionnement des EC2 pour le rechargement des données. Ces EC2 téléchargent les données et les stockent temporairement dans un bucket S3 via un script python. Les données de téléchargement sont au format NETCDF (format non structuré). Les logs générés par les scripts sont envoyés vers SPLUNK, qui est l’outil de gestion des logs applicatifs. A la fin du traitement, les EC2 s’étendent.
- Une template pour le provisionnement des EC2 pour la structuration des données téléchargées. Ces EC2 partitionnement les données téléchargées de façon à faciliter l’accès. Ils transforment ces données en format structurées (format parquet) pour faciliter la lecture et surtout l'exposition des données via Athena (SQL). Ces EC2 envoient aussi des metadata (liste des partitions, taille des fichiers) dans une table Dynamo, pour le contrôle de la qualité des données (profiling).
2.2.2. Chargement des données mensuelles
Le changement des données mensuelles possède les mêmes étapes que le chargement de la partie de chargement de données historiques. Les EC2 de téléchargement sont lancées par une fonction lambda. Cette dernière est déclenchée par un évènement type CRONTAB dans AWS cloudwatch. Les EC2 de téléchargements s’éteignent et lancent les EC2 de partitionnement. Au cours de la phase de structuration, les données sont partitionnées et transformées en séries temporelles. Ensuite, des tables Athena ont été créées pour permettre la consommation des données via des requêtes SQL. Les données sont exposées dans le lac de données pour permettre le partage.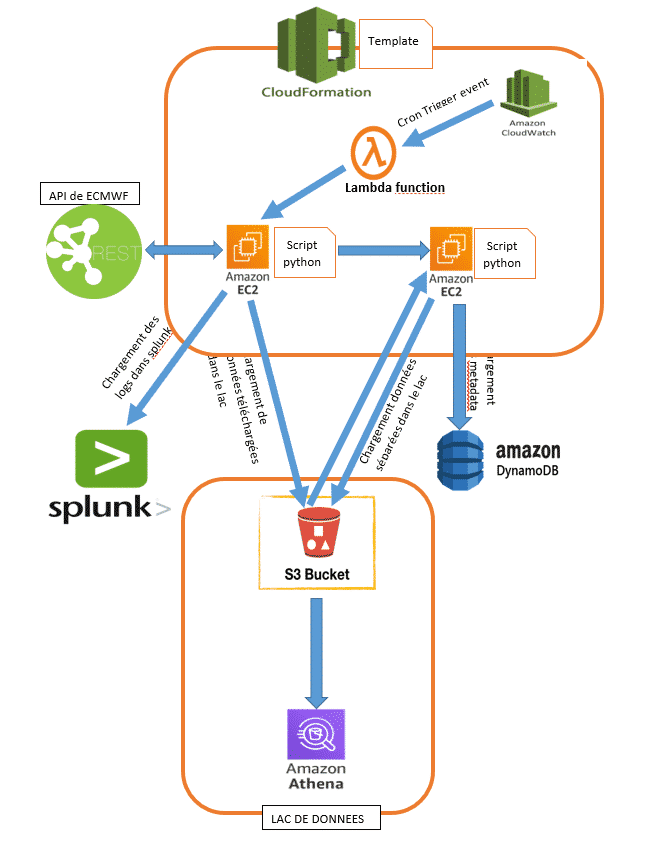
Partage
