

Azure : Quand une VM refuse de démarrer
 Le 01/06/2020
Le 01/06/2020Azure
Cloud
 5 minutes de lecture
5 minutes de lectureSommaire
Sommaire
Partage





Azure : Quand une VM refuse de démarrer
Description de l’erreur
Lors d’une tentative de démarrage d’une VM (status deallocated), le message d’erreur suivant apparait :
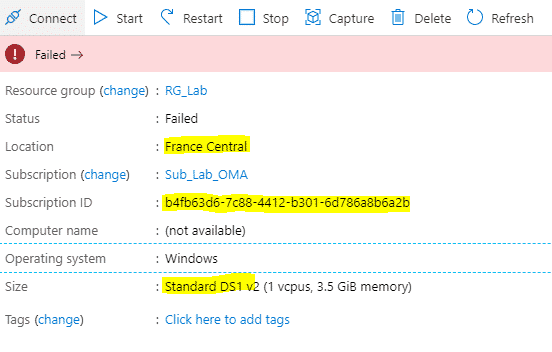
Vérifier les quotas
La première chose à vérifier lorsque nous sommes confrontés à un échec d’allocation de ressources est bien de vérifier qu’il y ait effectivement des ressources disponibles pour la VM à démarrer. En effet, la création d’une souscription ne donne pas accès à une quantité illimitée de ressources telles que les vCores ou le nombre de disques. A chaque souscription sont associés certains quotas, et lorsque ces quotas sont atteints, il est impossible de provisionner des ressources supplémentaires.
Pour vérifier le taux d’utilisation des ressources, il suffit d’aller dans la souscription concernée et de cliquer sur Usage + Quotas :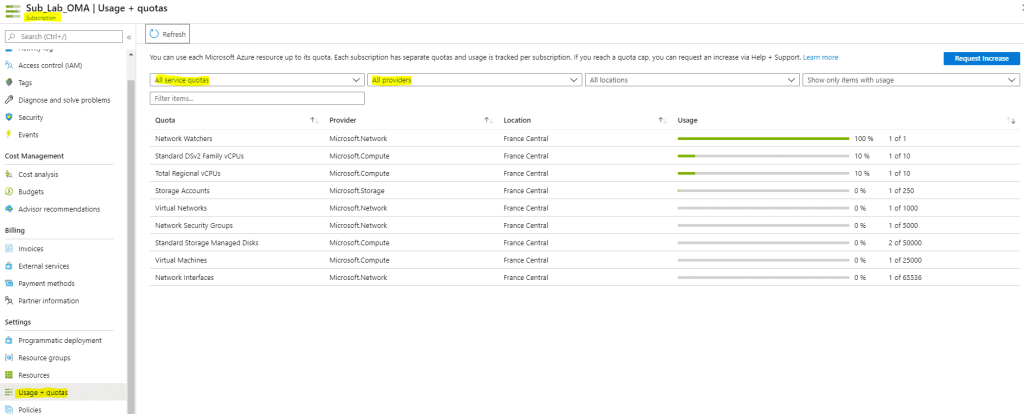 On constate dans le cas présent que les quotas ne sont pas atteints, la VM dispose bien des ressources disponibles pour démarrer.
On constate dans le cas présent que les quotas ne sont pas atteints, la VM dispose bien des ressources disponibles pour démarrer.
Vérifier que le modèle utilisé est toujours disponible
L’offre de Microsoft évolue sans cesse et les hyperviseurs hébergés dans les datacenters sont amenés à être remplacé. De la même manière, les modèles de VM suivent cette évolution : ainsi, les modèles ancienne génération sont progressivement remplacés par des modèles de nouvelle génération. Il peut arriver qu’une VM montée sur un modèle d’ancienne génération ne redémarre pas simplement parce que ce modèle n’est plus disponible dans la région concernée. Dans ce cas, il convient de vérifier la disponibilité du modèle pour la région concernée sur le site officiel de Microsoft qui recense les modèles de VM disponible par région.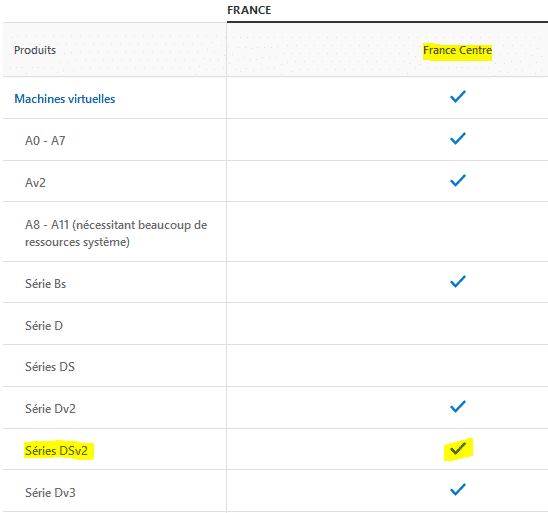 On constate dans le cas présent que le modèle de VM est toujours disponible dans la région de déploiement France Centre. Si toutefois le template n’était plus disponible, il suffirai alors de le changer pour que la VM redémarre normalement.
On constate dans le cas présent que le modèle de VM est toujours disponible dans la région de déploiement France Centre. Si toutefois le template n’était plus disponible, il suffirai alors de le changer pour que la VM redémarre normalement.
Redéploiement
Un simple de redéploiement de la VM peut régler le problème. En effet, il est possible que la demande d’allocation échoue car elle adresse un hyperviseur ou un cluster saturé (cf paragraphe suivant). Le plus simple dans ce cas consiste à accéder au Monitor à service health et à demander le redéploiement :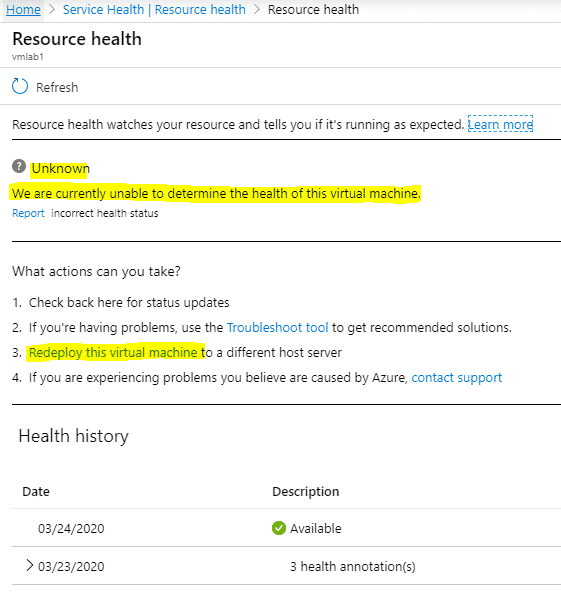
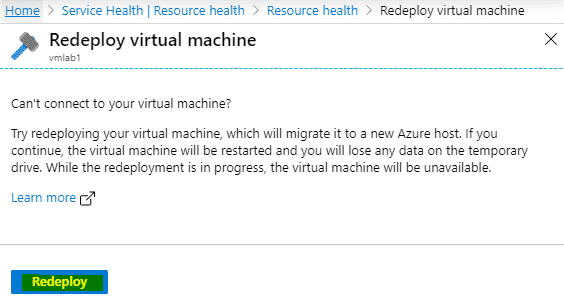 Pour autant, le redéploiement peut également échouer !
Pour autant, le redéploiement peut également échouer !
 Continuons donc notre analyse en introduisant la notion de cluster
Continuons donc notre analyse en introduisant la notion de cluster
Pinned Cluster
Les hyperviseurs dans les datacenters Azure sont répartis en clusters. Les allocations de ressources sont soumises à plusieurs clusters simultanément, ce qui permet ainsi d’augmenter la probabilité de répondre favorablement à la requête d’allocation tout en favorisant les allocations sur les clusters les moins chargés :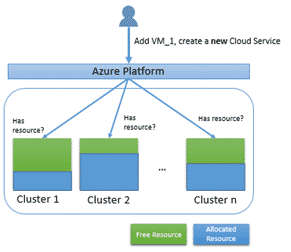 Mais il arrive que certaines demandes d’allocation ne soient envoyées qu’à un seul cluster, on parle de demande épinglée à un cluster ou pinned cluster. C’est le cas par exemple lorsque l’on ajoute une VM à un scale set existant ou un service cloud déjà déployé :
Mais il arrive que certaines demandes d’allocation ne soient envoyées qu’à un seul cluster, on parle de demande épinglée à un cluster ou pinned cluster. C’est le cas par exemple lorsque l’on ajoute une VM à un scale set existant ou un service cloud déjà déployé :
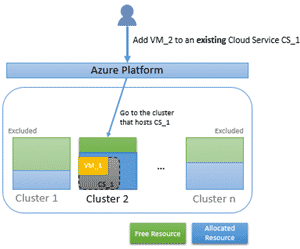 Une erreur d’allocation peut survenir lorsque le cluster ciblé ne dispose pas des ressources nécessaires, ou lorsque la demande d’allocation ne peut être honorée parce ce cluster ne dispose pas du modèle de VM demandé :
Une erreur d’allocation peut survenir lorsque le cluster ciblé ne dispose pas des ressources nécessaires, ou lorsque la demande d’allocation ne peut être honorée parce ce cluster ne dispose pas du modèle de VM demandé :
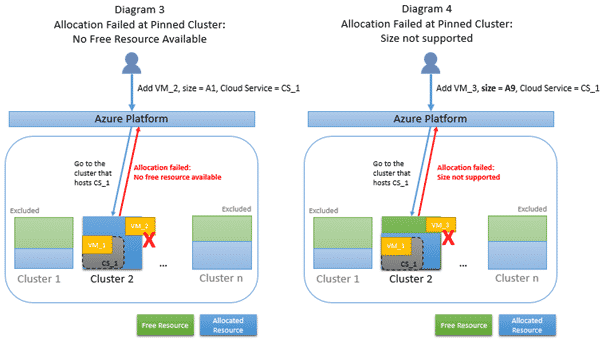 Il conviendra dans ce cas de changer le template de VM par un template supporté sur le cluster ou de libérer des ressources sur le cluster en réduisant la taille des services déjà déployés. Si l’une ou l’autre solution s’avère insatisfaisante, un appel au support Microsoft permettra de redéployer l’ensemble des services sur un cluster disposant des ressources nécessaires.
Il conviendra dans ce cas de changer le template de VM par un template supporté sur le cluster ou de libérer des ressources sur le cluster en réduisant la taille des services déjà déployés. Si l’une ou l’autre solution s’avère insatisfaisante, un appel au support Microsoft permettra de redéployer l’ensemble des services sur un cluster disposant des ressources nécessaires.
Incident azure
Enfin, l’ultime cause peut provenir d’une défaillance plus générale dans les datacenters azure. Dans ce cas, Service health sera le bon point d’entrée pour vérifier la disponibilité du service. L’écran ci-dessous illustre un incident survenu en région France Central, empêchant le déploiement de certain template de VM :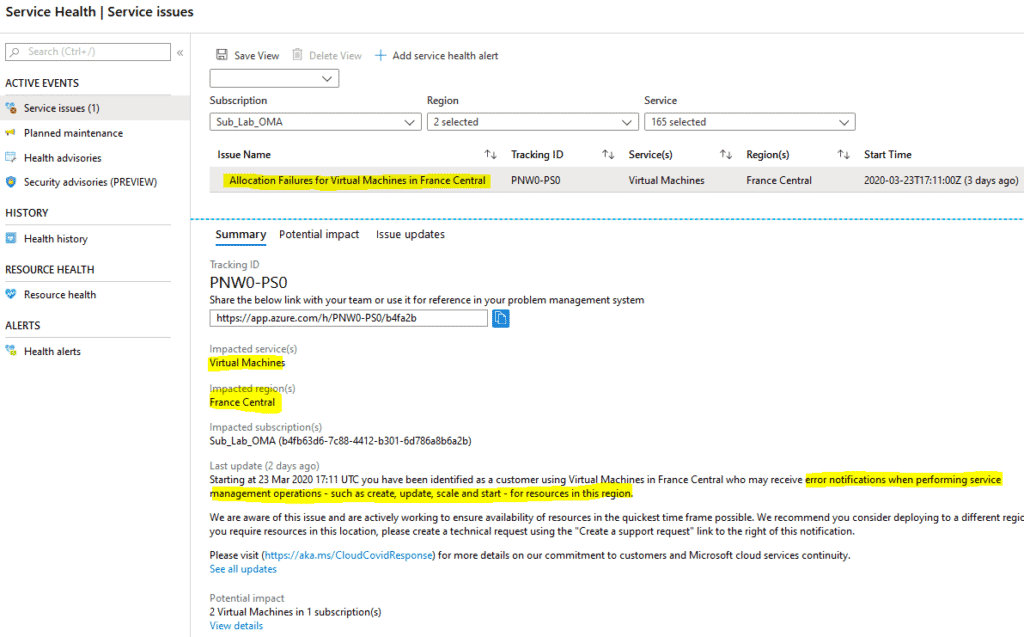 Il n'y a rien de plus à faire dans ce cas que d'ouvrir un incident au support microsoft et convenir avec eux de la marche à suivre.
Il n'y a rien de plus à faire dans ce cas que d'ouvrir un incident au support microsoft et convenir avec eux de la marche à suivre.
Conclusion
Il peut arriver qu’un simple reboot de VM échoue du fait de problème d’allocation de ressources au niveau de la fabrique azure. Aussi, se familiariser avec Azure monitor et Service health, ainsi qu'avec tous les moyens de solutionner ce type de problème nous permettra d’être plus réactif lorsque nous serons confrontés à cette situation. Bon cloud à tous !Partage
