

AWS DeepRacer : banalisation du Reinforcement Learning (RL)
 Le 30/11/2020
Le 30/11/2020AWS
Cloud
 3 minutes de lecture
3 minutes de lectureSommaire
Sommaire
Partage





AWS DeepRacer : banalisation du Reinforcement Learning (RL)
Principes de base
Le principe est simple, le graphe ci-dessous schématise le fonctionnement du RL et les acteurs :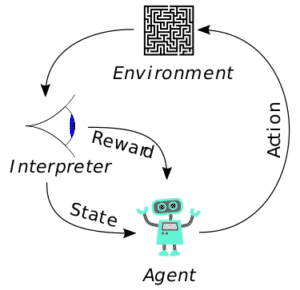
Image: Wikipédia
Un Agent robot, dans un environnement donné, prend des actions plus au moins bonnes, l’interpréteur fait part à l’agent des récompenses acquise (ou pénalités) et des paramètres de l’environnement. Donc, l’idée est que l’agent prenne beaucoup d’actions et constitue une base d’expériences qu’on appellera "Model". Ce Model sera amélioré au fur et à mesure des itérations pour faire des actions avec plus de récompenses, donc pertinentes. Mais on laisse quand même l’agent faire des actions arbitraires ou non contrôlées pour explorer de nouvelles possibilités que celle qu'il a pris l'habitude de prendre. En pratique, le grand défit est de définir ce qu'est une Récompense : c’est une fonction (reward function) qui selon l’observation des paramètres de l’environnement va retourner un score de la dernière action menée (Ex : -10 si on sort de la chaussée et +5 si on garde les 4 roues dans le couloir). Assez de théorie et place à l’amusement.AWS DeepRacer
AWS DeepRacer offre un service complet d’implémentation des Modèles RL pour des courses de voitures miniatures 1/18, très simple à utiliser pour s’initier au RL. Il suffit d’adapter une fonction d’évaluation pour faire sa propre « IA » de compétition, la simulation, gestion des capteurs d’environnement, l’environnement informatique les Frameworks (Tensorflow…) et la puissance de calcul sont encapsulés pour nous. Une fois le modèle est créé et entrainé, on peut l’utiliser en simulation ou dans une vraie mini-voiture de course pour tester et voir ses performances. Voici les quelques étapes pour créer un premier modèle RL de course :1. Création d'un nouveau Model avec le service DeepRacer

2. Choix du type de course

3. Choix du circuit d'entrainement (Pas nécessairement celui de la compétition)


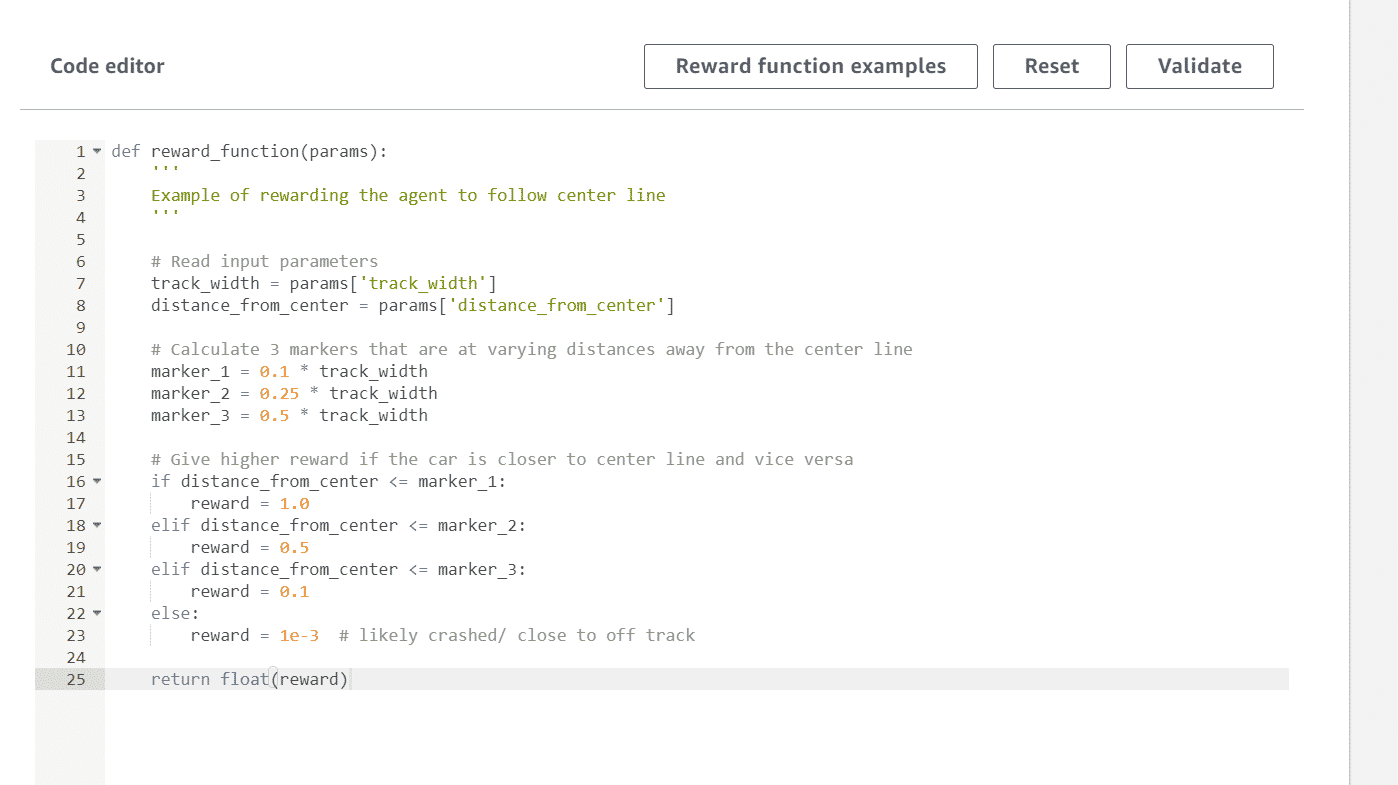
4. Définition de la fonction de récompense (Python)

5. Validation et c'est parti pour une heure d'entrainement en mode accéléré

Pendant la durée d'entrainement, le graphe de suivi se met à jour pour voir l'avancée de l'apprentissage.
J'ai mis un graphe au début et le graphe final :
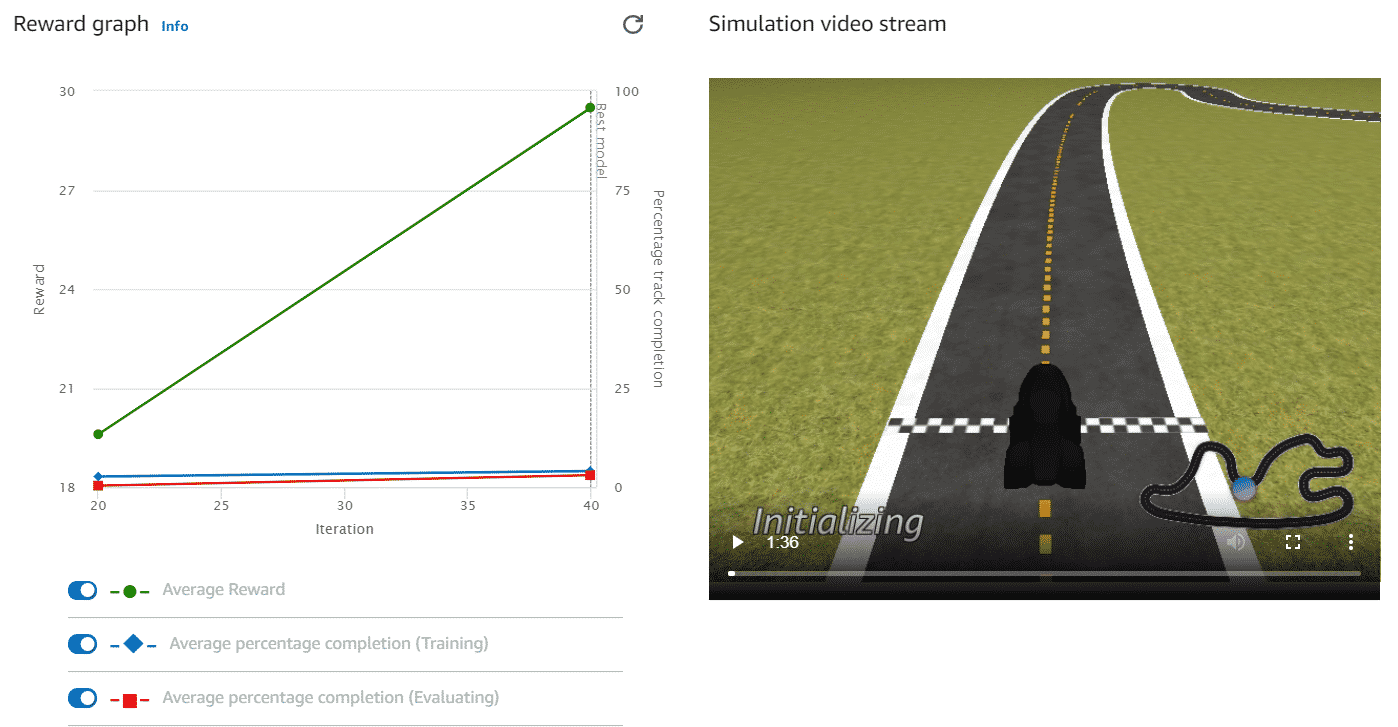 Au début l'agent apprend rapidement à chercher les récompenses en restant sur la chaussée, mais on est loin d'avoir un robot capable de franchir la ligne d'arrivée.
Au début l'agent apprend rapidement à chercher les récompenses en restant sur la chaussée, mais on est loin d'avoir un robot capable de franchir la ligne d'arrivée.
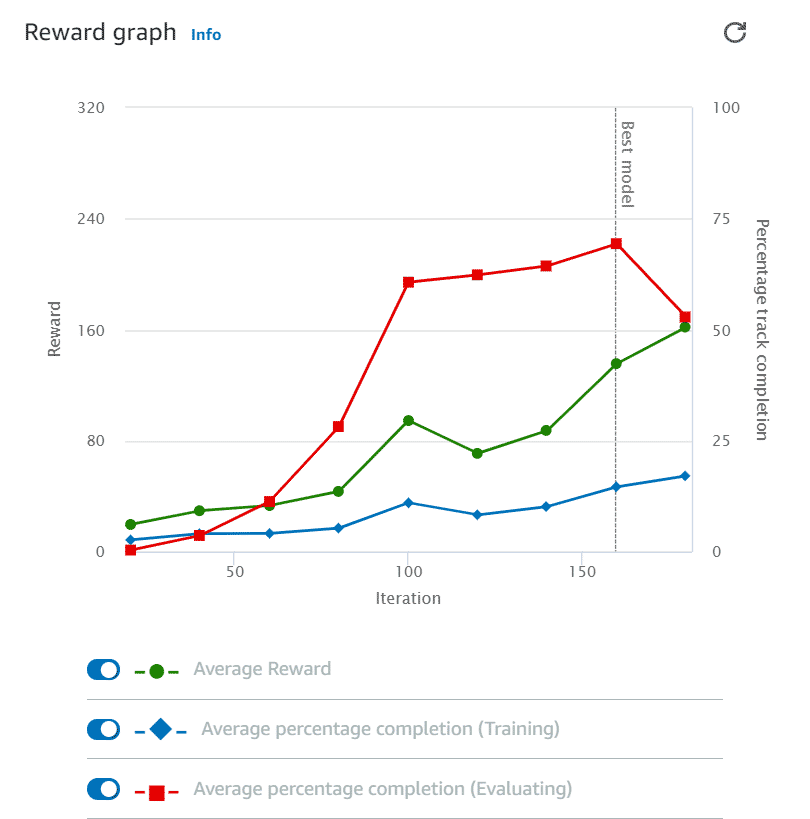 A la fin de l'entrainement d'un durée d'une heure, le modèle a déjà vu un très grand nombre de cas de figures, ses actions sont plus prévisibles et pertinentes, mais ce n'est pas encore suffisant pour inquiéter Lewis Hamilton.
A la fin de l'entrainement d'un durée d'une heure, le modèle a déjà vu un très grand nombre de cas de figures, ses actions sont plus prévisibles et pertinentes, mais ce n'est pas encore suffisant pour inquiéter Lewis Hamilton.

Partage
