Mon but dans cette série d’articles n’est pas de faire une conférence sur Kubernetes, ou K8s (K[ubernete]s), mais de déployer un exemple simple mettant en œuvre une application minimaliste de microservices sur EKS. La simplicité de déploiement de K8s on premise n’est pas la première de ses qualités, loin s’en faut. L’objectif est de mettre en évidence la rapidité de déploiement de K8s dans le Cloud AWS lorsqu’il est déployé sous forme de service EKS. Le déploiement d’EKS donnera matière à réaliser le déploiement d’une application mettant en avant le lien entre EKS et les services AWS, notamment le load balancer.
Cet article est en trois parties :
- La première partie, celle-ci, donne les principes mis en œuvre.
- La deuxième partie décrit la création du cluster EKS. Il y a seulement trois commandes : une première commande de création du cluster, une deuxième commande d’établissement de connexion entre un serveur client et le Kubernetes Master. Une troisième commande de contrôle de cette connexion.
- La troisième partie utilise des containers dockers dont l’image est disponible en téléchargement sur docker.com. Les fichiers de paramétrage yaml pour K8s seront aussi disponible quant à eux sur Github. Il existe une application de démo disponible sur kubernetes.io (https://kubernetes.io/docs/tutorials/stateless-application/guestbook). Cependant, nous partirons d’une application encore plus simple, minimaliste, pour comprendre quelques fondements de Kubernetes.
Quelques idées avant de commencer
Les containers
Les containers ont le vent en poupe actuellement, pas simplement parce que c’est la mode, mais aussi parce qu’ils apportent de la nouveauté dans le monde de la virtualisation. Notamment et parmi d’autres qualités, la containérisation permet d’augmenter la densité des ressources par l’accès direct au système d’exploitation faisant tourner le moteur de containers, sans intermédiaire d’un hyperviseur. En effet, dans les conteneurs, il n’y a pas d’OS virtualisé, c’est l’OS hôte qui est utilisé à l’intérieur des containers. D’autres fonctionnalités intéressent leurs promoteurs : environnement de développement porté tel quel en production par copie des conteneurs, démarrage pratiquement immédiat des containers, ce qui permet de créer des applications à la demande, avec une mutualisation de ressources à grande échelle, comme par exemple les fonctions Lambda chez AWS.
Kubernetes
Pour faire fonctionner les containers en haute-disponibilité avec une notion de cluster, permettre le partage de ressources réseaux et stockage, mettre à l’échelle des applications (augmenter ou réduire le nombre de containers manuellement ou automatiquement pour l’adapter à une charge), assurer le lien entre des éléments fournis dans une infrastructure Cloud et les containers, il faut un mécanisme dit orchestrateur de containers.
Kubernetes est actuellement leader dans l’orchestration des containers, et il est en passe de gagner la bataille ? Conçu à l’origine par des ingénieurs de chez Google, celui-ci fonctionne aussi dans le Cloud AWS sous la forme du service EKS. L’avantage d’utiliser Kubernetes dans sa forme EKS est tout d’abord de pouvoir s’appuyer sur une infrastructure Cloud pour faire tourner le cluster. Ensuite, et ce n’est pas le moindre, EKS masque la complexité d’installation de K8s et aussi sa maintenance. Il existe aussi un orchestrateur de containers de fourniture AWS, ECS ; il sera peut-être l’objet d’un autre article.
L’architecture de l’application micro services qui va être déployée
L’application qui va être déployée est sans prétention et sa finalité n’est que pédagogique. Si elle atteint son but, tant mieux. Il s’agit d’un serveur nginx qui redirige, suivant l’URL reçue, la demande HTTP sur un des serveurs Apache responsable de ce micro-service (/vert ou /marron). OK, je sais, des serveurs Apache derrière nginx … Bon ! Comme je l’ai dit plus haut, c’est pour l’exemple.
Vision applicative
L’application est constituée en frontal d’un serveur nginx qui redirige sur le serveur apache1 les demandes sur l’URL /marron, sur le serveur apache2 les demandes sur l’URL /vert. En cas de non spécification d’URL, le serveur nginx affiche un message demandant d’entrer l’une ou l’autre des URL.
Dans le fichier nginx.conf, les serveurs Apache sont connus sous le nom que leur affecte le service attaché aux pods : apache1 ou apache2. La redirection d’URL est définie dans le fichier nginx.conf.
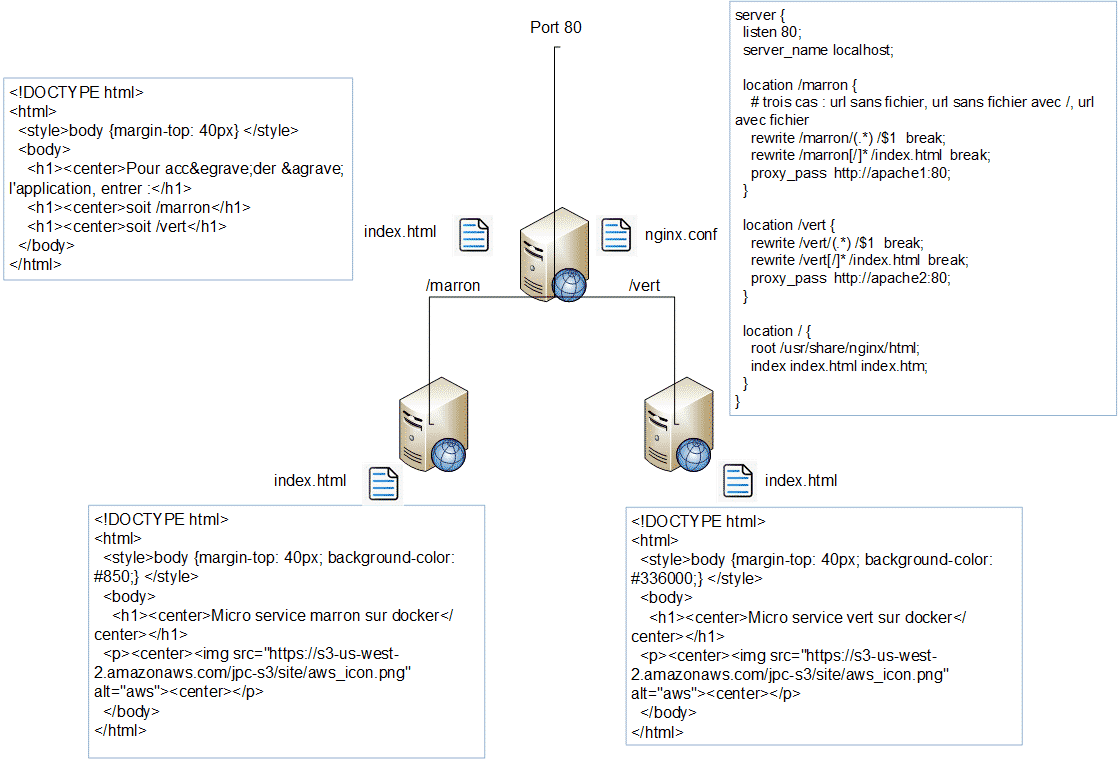
Vision Docker
Chacun des serveurs ci-dessus est installé sur un container docker utilisant une image minimaliste linux. L’installation des serveurs sur des containers docker n’est pas le sujet de cet article. Cependant, voici le fil conducteur dans le cas où vous voulez vous-même reconstruire les images docker.
- Exporter la variable d’environnement suivante qui vous permet de définir le repository (utilisée dans le fichier docker-compose.yml pour préfixer le nom de l’image, donc partie avant le ‘/’).
# export DOCKER_REGISTRY=jpcarret
- Cloner les fichiers de création des containers
# git clone https://github.com/jean-pierre-carret/marron-vert-docker
- Se positionner dans le répertoire
# cd marron-vert-docker
- Créer les images docker avec la commande docker-compose. Docker et docker-compose doivent auparavant être installés sur le serveur local.
# docker-compose build
Envoyer les images sur le repository (créé auparavant sur docker.com)
# docker login # docker push jpcarret/docker_apache1:latest # docker push jpcarret/docker_apache2:latest # docker push jpcarret/docker_apache2:latest
Vision EKS
Les images docker vont être utilisées dans des pods. Le pod est l’unité de base qui contiendra un ou plusieurs containers docker. Pour notre projet, un pod = un docker (je ne rentre pas dans le détail). Les pods vont être déployés à l’aide de deployments et reliés du point de vue réseau grâce aux services.
Chaque deployment (donc ensemble de pods identiques) sera réparti sur les différents nœuds du cluster EKS. Cela permet de répartir la charge et de réaliser une haute disponibilité des pods au sein du cluster, répartis eux mêmes au sein des différentes zones de disponibilités AWS.
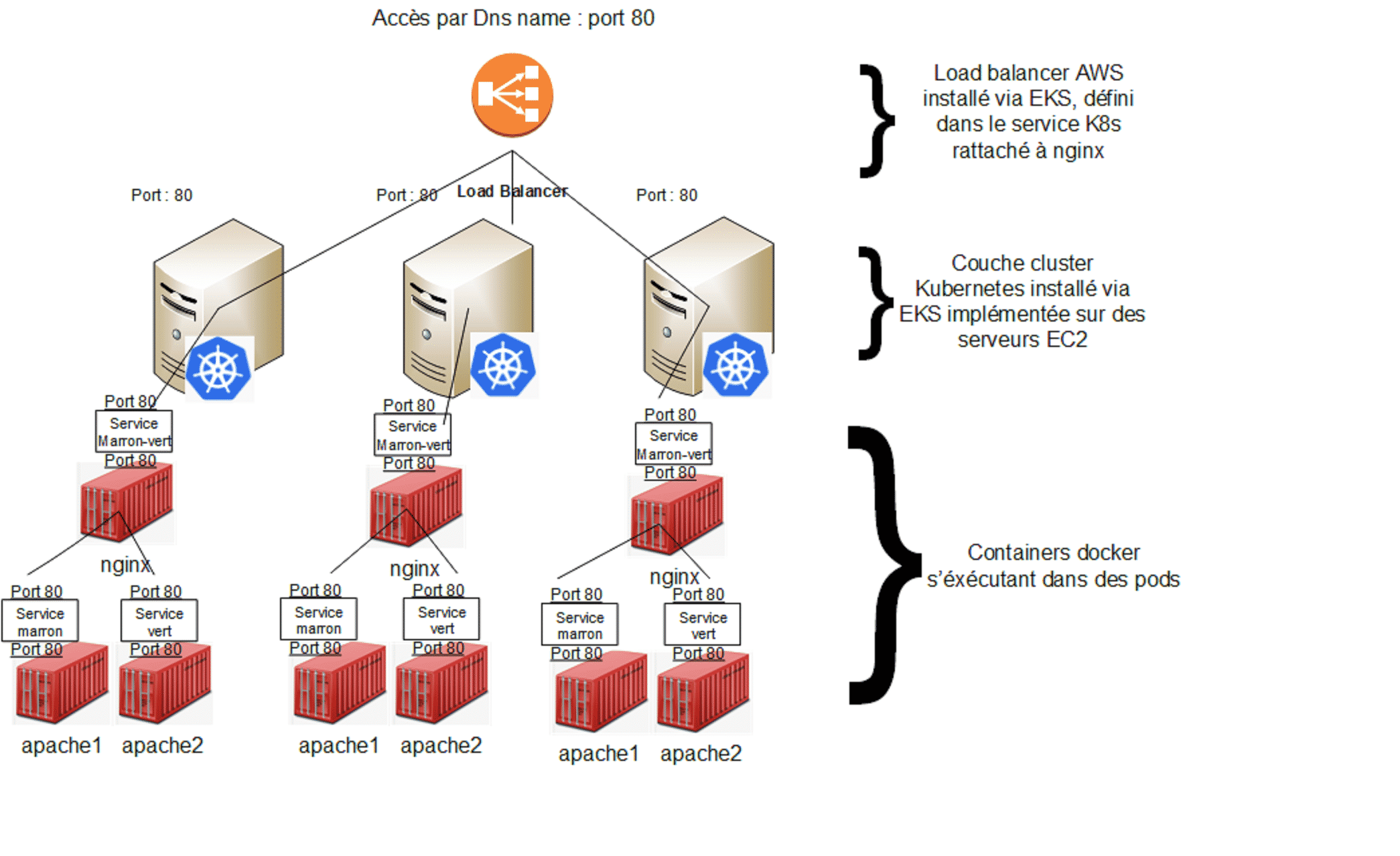
C’est cette architecture qui va être déployée dans les deux autres parties de cet article.
Et si vous souhaitez vous former sur Amazon Web Services, découvrez notre offre de formations AWS.
