

MS SQL Server Data Partitioning
 Le 08/04/2020
Le 08/04/2020 9 minutes de lecture
9 minutes de lecture




MS SQL Server Data Partitioning
1. Introduction
Il y a quelques temps, je suis intervenu chez un client qui avait un problème de performance d’une requête de purge dans son DW.
La requête en question fait un DELETE d’environ 50 millions de lignes, et comme la table en question ne contient pas d’index j’ai créé un index cluster sur la colonne Date qui nous a fait gagner 50% de temps d’exécution. Mais le client ne pouvait pas se permettre de verrouiller la table pendant la durée d’exécution de la requête. Donc, afin d’aider à améliorer davantage la purge des données, on a proposé SQL Server Data Partitioning afin de bénéficier d’amélioration des performances de requête et de purge de millions de lignes instantanément.
En effet, le partitionnement peut améliorer l’extensibilité, réduire la contention et optimiser les performances. Il peut également offrir un mécanisme pour la division des données à l’aide d’un modèle d’utilisation.
Dans notre cas de purge, SQL Server préfère utiliser l'instruction TRUNCATE TABLE plutôt que l'instruction DELETE, car elle est plus rapide, journalisée de façon minimale et consomme moins de ressources serveur. L'inconvénient de l'instruction TRUNCATE TABLE est qu'elle supprime toutes les lignes de table, car aucune clause WHERE ne peut être ajoutée à l'instruction pour spécifier les critères de suppression. Alors, comment pourrions-nous obtenir les avantages de l'instruction TRUNCATE TABLE sans supprimer toutes les lignes de la table ?
La solution est d’utiliser TRUNCATE TABLE avec l’option WITH PARTITIONS () spécifiant la partition ou les ensembles de partitions.
Mais pour utiliser cette syntaxe, il faut savoir où résident les données (dans quelle partition) et il faut s’assurer aussi que les données d’autres tables ne résident pas dans cette partition.
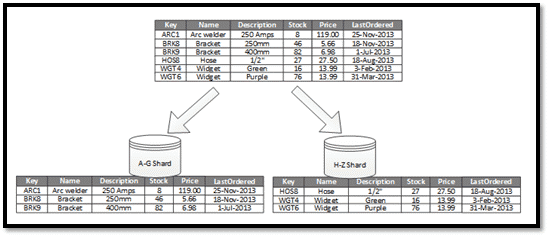
2. SQL Server Data Partitioning
Le SQL Server Data Partitioning permet de diviser les données d’une table d’une base de données SQL Server en partitions qui peuvent être gérées et auxquelles on peut accéder séparément. Le partitionnement peut améliorer l’extensibilité, réduire la contention et optimiser les performances. Il peut également offrir un mécanisme pour la division des données à l’aide d’un modèle d’utilisation.
3. Avantages du Partitionnement
- Améliorer l’évolutivité : Quand on a une table sur un disque qui est saturé.
- Amélioree les performances : Les opérations qui affectent plusieurs partitions peuvent s’exécuter en parallèle.
- Améliorer la sécurité : Dans certains cas, vous pouvez séparer les données sensibles et non sensibles dans différentes partitions et appliquer différents contrôles de sécurité aux données sensibles.
- Procurer une flexibilité opérationnelle : Le partitionnement offre de nombreuses possibilités pour affiner les opérations, optimiser l’efficacité administrative et réduire les coûts.
- Pouvoir utiliser TRUNCATE TABLE avec la clause Where.
4. Implémentation d’un Partitionnement
Nous allons procéder aux partitionnements d’une table nommée TablePartition dans une base de données nommée SQLPartition.4.1. Création d’une Base de données de test
CREATE DATABASE [SQLPartitionDB] CONTAINMENT = NONE ON PRIMARY ( NAME = N'SQLPartition', FILENAME = N'F:\DataDB\SQLPartition.mdf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) LOG ON ( NAME = N'SQLPartition_log', FILENAME = N'F:\LogDB\SQLPartition_log.ldf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) GO
4.2. Préparer les nouveaux groupes de fichiers
USE [master] GO ALTER DATABASE [SQLPartitionDB] ADD FILEGROUP [Trim1] GO ALTER DATABASE [SQLPartitionDB] ADD FILEGROUP [Trim2] GO ALTER DATABASE [SQLPartitionDB] ADD FILEGROUP [Trim3] GO ALTER DATABASE [SQLPartitionDB] ADD FILEGROUP [Trim4] GO
4.3. Préparer les nouveaux fichiers de données
USE [master] GO ALTER DATABASE [SQLPartitionDB] ADD FILE ( NAME = N'Trim1_2020', FILENAME = N'F:\DataDB\Trim1_2020.ndf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [Trim1] GO ALTER DATABASE [SQLPartitionDB] ADD FILE ( NAME = N'Trim2_2020', FILENAME = N'F:\DataDB\Trim2_2020.ndf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [Trim2] GO ALTER DATABASE [SQLPartitionDB] ADD FILE ( NAME = N'Trim3_2020', FILENAME = N'F:\DataDB\Trim3_2020.ndf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [Trim3] GO ALTER DATABASE [SQLPartitionDB] ADD FILE ( NAME = N'Trim4_2020', FILENAME = N'F:\DataDB\Trim4_2020.ndf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [Trim4] GO
4.4. Création d’une fonction de partition
Une fonction de partition SQL Server spécifie le mode de partitionnement d’une table ou index et comment les lignes d'une table ou d'un index sont mappées à un ensemble de partitions en fonction des valeurs de certaines colonnes, appelées « colonnes de partitionnement ».
Dans notre cas, nous allons créer une fonction de partitionnement avec une colonne de partitionnement de type Date et de limite de partitionnement par trimestre de l’années 2020 :
USE [SQLPartitionDB] GO CREATE PARTITION FUNCTION [PartitionByDate](date) AS RANGE RIGHT FOR VALUES (N'2020-03-31T00:00:00.000', N'2020-06-30T00:00:00.000', N'2020-09-30T00:00:00.000', N'2020-12-31T00:00:00.000') GO
4.5. Création d'un Schéma de partition
Un schéma de partition met en correspondance les partitions produites par une fonction de partition et un jeu de groupes de fichiers définis par l'utilisateur.
Dans notre cas, nous avons créé 4 valeurs de limite qui imposent au moins 5 partitions :
- Partition 1 [Trim1], de – l’infini à 2020-03-30
- Partition 2 [Trim2], de 2020-03-31 à 2020-06-29
- Partition 3 [Trim3], de 2020-06-30 à 2020-09-29
- Partition 4 [Trim4], de 2020-09-30 à 2020-12-30
- Partition 5 [PRIMARY], de 2020-12-31 à + l’infini
USE [SQLPartitionDB]
GO
CREATE PARTITION SCHEME [PartitionByDateScheme]
AS PARTITION [PartitionByDate]
TO ([Trim1],
[Trim2],
[Trim3],
[Trim4],
[PRIMARY])
GO
4.6 Création d’une table partitionnée
USE [SQLPartitionDB] GO CREATE TABLE [dbo].[TablePrtition]( [Client] [nvarchar](64) NOT NULL, [UserThread] [int] NOT NULL, [Id] [uniqueidentifier] ROWGUIDCOL NOT NULL, [Server] [nvarchar](64) NOT NULL, [Data] [int] NOT NULL, [AccessCount] [int] NOT NULL, [Username] [nvarchar](256) NULL, [Document] [image] NULL, [DocumentType] [nvarchar](50) NULL, [Date] [date] NULL, CONSTRAINT [PK_TbPartion] PRIMARY KEY NONCLUSTERED ( [Id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PartitionByDateScheme] ([Date]) GO ALTER TABLE [dbo].[TablePrtition] ADD DEFAULT (newid()) FOR [Id] GO ALTER TABLE [dbo].[TablePrtition] ADD DEFAULT ((1)) FOR [AccessCount] GO ALTER TABLE [dbo].[TablePrtition] ADD DEFAULT (suser_sname()) FOR [Username] GO
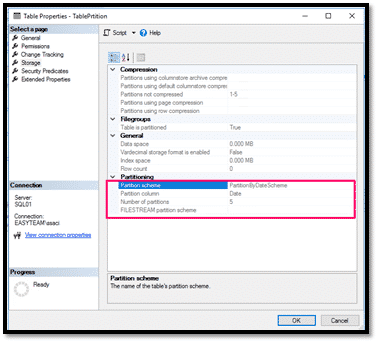
4.7. Fonctions Système
Les fonctions système effectuent des opérations et retournent des informations concernant les valeurs, les objets et les paramètres de SQL Server.
Pour notre cas, on peut utiliser la fonction système $PARTITION, qui retourne le numéro de la partition dans laquelle un ensemble de valeurs de colonnes de partitionnement doit être mappé afin de pouvoir être utilisé par une fonction de partition précise.
On prend, dans notre cas, les valeurs de limite définies dans le chapitre "Création d'un schéma de partition" :
- Partition 1 [Trim1], de – l’infini à 2020-03-31
- Partition 2 [Trim2], de 2020-04-01 à 2020-06-30
- Partition 3 [Trim3], de 2020-07-01 à 2020-09-30
- Partition 4 [Trim4], de 2020-10-01 à 2020-12-31
- Partition 5 [PRIMARY], de 2021-01-01 à + l’infini
SELECT ('2019-01-01') as Date, $PARTITION.PartitionByDate('2019-01-01') AS PartitionNumber ;
GO
SELECT ('2020-03-30') as Date, $PARTITION.PartitionByDate('2020-03-30') AS PartitionNumber ;
GO
SELECT ('2020-03-31') as Date,$PARTITION.PartitionByDate('2020-03-31') AS PartitionNumber ;
GO
SELECT ('2020-06-29') as Date,$PARTITION.PartitionByDate('2020-06-29') AS PartitionNumber ;
GO
SELECT ('2020-06-30') as Date,$PARTITION.PartitionByDate('2020-06-30') AS PartitionNumber ;
GO
SELECT ('2020-09-29') as Date,$PARTITION.PartitionByDate('2020-09-29') AS PartitionNumber ;
GO
SELECT ('2020-09-30') as Date,$PARTITION.PartitionByDate('2020-09-30') AS PartitionNumber ;
GO
SELECT ('2020-12-30') as Date,$PARTITION.PartitionByDate('2020-12-30') AS PartitionNumber ;
GO
SELECT ('2020-12-31') as Date,$PARTITION.PartitionByDate('2020-12-31') AS PartitionNumber ;
GO
SELECT ('2021-01-01') as Date,$PARTITION.PartitionByDate('2021-01-01') AS PartitionNumber ;
GO

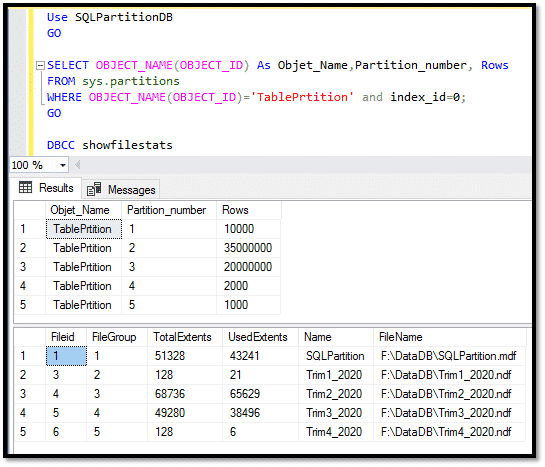
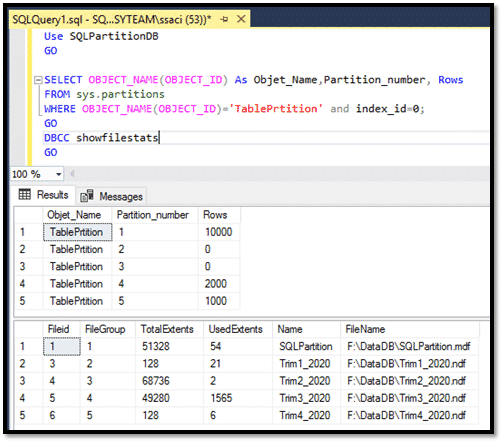
On peut aussi savoir le nombre d’enregistrements de chaque partition avec la requête ci-dessous :
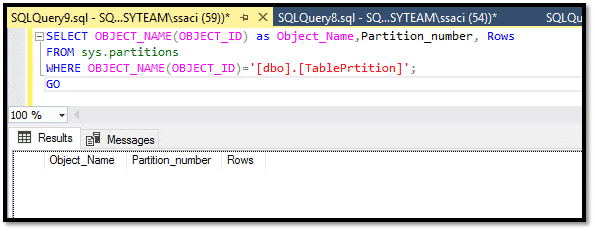
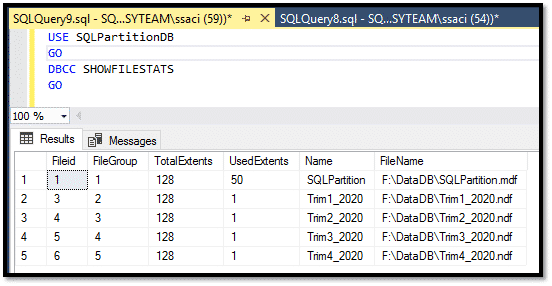
On peut aussi voir par la commande DBCC SHOWFILESTATS, la consommation d’espace pour chaque fichier de données et par conséquent par partition dans notre cas :
4.8. Insertion des Données
Pour la suite de notre exemple, nous allons insérer :
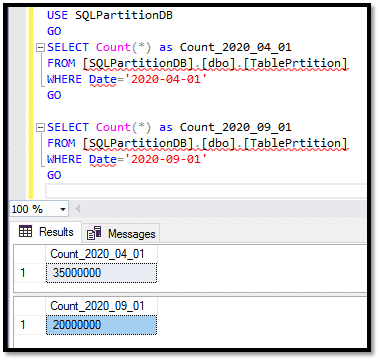
- 5000 enregistrements avec la date 2019-01-01,
- 4000 enregistrements avec la date 2020-04-01,
- 3000 enregistrements avec la date 2020-09-01,
- 2000 enregistrements avec la date 2020-10-01,
- 1000 enregistrements avec la date 2021-01-01.
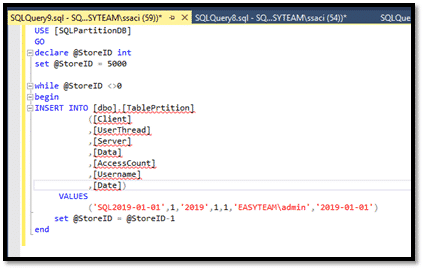
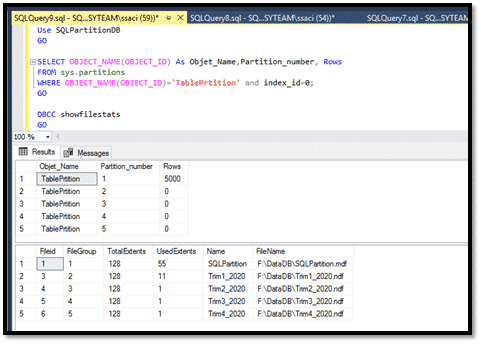
Donc, nous avons 5000 enregistrements ou lignes dans la partition 1, c’est-à-dire les 5000 enregistrements situés physiquement sur le fichier Trim1_2020.ndf.
On insère maintenant 4000 enregistrements avec la date 2020-04-01 :
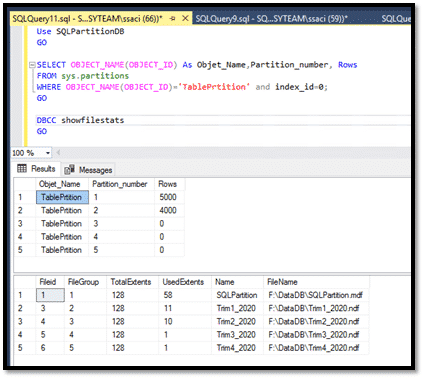 Et, à la fin de nos insertions, nous aurons :
Et, à la fin de nos insertions, nous aurons :
- 5000 enregistrements avec la date 2019-01-01, enregistrés physiquement sur le fichier Trim1_2020.ndf
- 4000 enregistrements avec la date 2020-04-01, enregistrés physiquement sur le fichier Trim2_2020.ndf
- 3000 enregistrements avec la date 2020-09-01, enregistrés physiquement sur le fichier Trim3_2020.ndf
- 2000 enregistrements avec la date 2020-10-01, enregistrés physiquement sur le fichier Trim4_2020.ndf
- 1000 enregistrements avec la date 2021-01-01, enregistrés physiquement sur le fichier SQLPartition.mdf
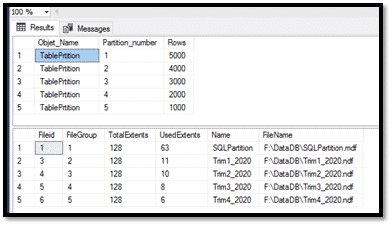
5. TRUNCATE TABLE avec la clause WITH PARTITIONS
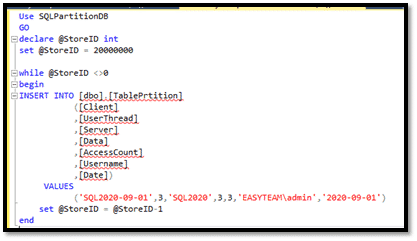
On va faire un chargement de masse de 35 Millions de lignes sur la partition numéro 2 avec une date toujours de 2020-04-01 et un autre chargement de 20 Millions de lignes sur la partition numéro 3 avec une date de 2020-09-01. 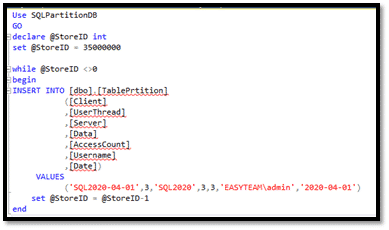
A cette étape, on va supprimer tous les enregistrements qui ont la colonne date='2020-09-01' (20 Millions d’enregistrements) avec un DELETE et la clause WHERE. Et on va supprimer tous les enregistrements qui ont la colonne date= '2020-04-01' avec un TRUNCATE WITH PARTITIONS. Et on va voir le temps d’exécution de chaque requête.
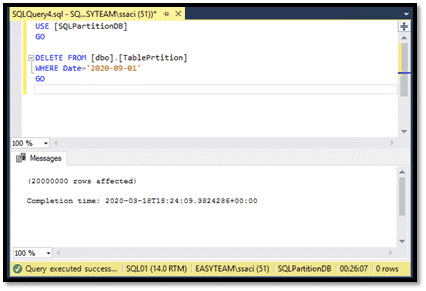
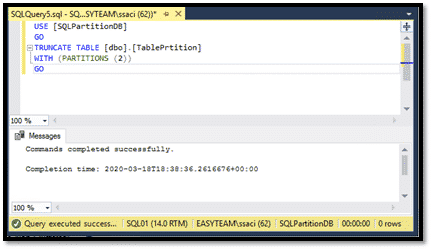
Donc, pour supprimer 20 Millions de lignes avec un Delete, il a fallu une vingtaine de minutes, et pour supprimer 35 Millions de lignes avec un Truncate, ce fut instantané.
