

Mettre en place des compteurs PerfMon
 Le 31/05/2021
Le 31/05/2021SQL Server
SSIS - SQL Server Integration Services
 8 minutes de lecture
8 minutes de lectureSommaire
Sommaire
Partage





Mettre en place des compteurs PerfMon
1. Introduction
Afin de connaitre la volumétrie des données échangées ENTREE/SORTIE lors d’une exécution des package SSIS et avoir une idée générale des performances des serveurs SSIS et Base de données SQL Server, nous allons passer par les statistiques de performance.1.1. Objet
L’objectif de cet article est de montrer comment on procède pour une collecte des compteurs de performances SQL Server et SSIS via l’outils PerfMon.2. PerfMon
PerfMon ou Performance Monitor est un outil de supervision sous les systèmes Windows, il permet de collecter les métriques des compteurs des performances, afin de les exploiter pour voir évoluer les performances d’une application ou de calculer la volumétrie d’échanges des données pour les applications.2.1. Les compteurs utilisé dans notre cas
Nous allons utiliser les compteurs suivants :| Compteurs | Descriptifs |
| SQLServer: Buffer Manager : Buffer cache hit ratio | Indicates the percentage of pages found in the buffer cache without having to read from disk. |
| SQLServer: Buffer Manager : Checkpoint pages/sec | Indicates the number of pages flushed to disk per second by a checkpoint or other operation that require all dirty pages to be flushed. |
| SQLServer: Buffer Manager : Lazy writes/sec | Indicates the number of buffers written per second by the buffer manager's lazy writer. |
| SQLServer: Buffer Manager : Page Life Expectancy | Indicates the number of seconds a page will stay in the buffer pool without references. |
| SQLServer: SQL Statistics: Batch Requests/Sec | Number of Transact-SQL command batches received per second. This statistic is affected by all constraints (such as I/O, number of users, cache size, complexity of requests, and so on). High batch requests mean good throughput. |
| SQLServer: SQL Statistics: SQL Compilations/sec | Number of SQL compilations per second. Indicates the number of times the compile code path is entered. |
| SQLServer: SQL Statistics: SQL Re-Compilations/sec | Number of statement recompiles per second. Counts the number of times statement recompiles are triggered |
| LogicalDisk : Avg. Disk sec/Read | Indicates how fast data is being read on average for a specific logical disk. |
| LogicalDisk : Avg. Disk sec/Write | Indicates how fast data is being written on average for a specific logical disk. |
| LogicalDisk : Current Disk Queue Length | Indicates the number of requests outstanding on the disk at the time the performance data is collected |
| Memory: Available Mbytes | Indicates the Available MBytes is the amount of memory that is available for use by applications and processes. |
| Memory: Commit Limit | is the amount of virtual memory that can be committed without having to extend the paging file(s). |
| Memory: Committed Bytes | is the amount of committed virtual memory while Commit Limit is the amount of virtual memory that can be committed without having to extend the paging file(s). |
| Process: %Processor Time | is the percentage of elapsed time that all of process threads used the processor to execution instructions. |
| Processor: %Privileged time | is the percentage of elapsed time that the process threads spent executing code in privileged mode |
| Processor: %Processor Time | is the percentage of elapsed time that the processor spends to execute a non-Idle thread. It is calculated by measuring the percentage of time that the processor spends executing the idle thread and then subtracting that value from 100%. |
| Network interface: Bytes Total/sec | is the rate at which bytes are sent and received over each network adapter, including framing characters. |
| Network interface: Output Queue Length | is the length of the output packet queue (in packets). If this is longer than 2, delays occur. |
| Network interface: Current Bandwidth | is an estimate of the current bandwidth of the network interface in bits per second |
| SQLServer: SSIS Pipeline xx.0: BLOB bytes read | The number of bytes of binary large object (BLOB) data that the data flow engine has read from all sources. |
| SQLServer: SSIS Pipeline xx.0: BLOB bytes written | The number of bytes of BLOB data that the data flow engine has written to all destinations. |
| SQLServer: SSIS Pipeline xx.0: BLOB files in use | The number of BLOB files that the data flow engine currently is using for spooling. |
| SQLServer: SSIS Pipeline xx.0: Buffer memory | The amount of memory that is in use. This may include both physical and virtual memory. When this number is larger than the amount of physical memory, the Buffers Spooled count rises as an indication that memory swapping is increasing. Increased memory swapping slows performance of the data flow engine. |
| SQLServer: SSIS Pipeline xx.0: Buffers in use | The number of buffer objects, of all types, that all data flow components and the data flow engine is currently using. |
| SQLServer: SSIS Pipeline xx.0: Buffers spooled | The number of buffers currently written to the disk. If the data flow engine runs low on physical memory, buffers not currently used are written to disk and then reloaded when needed. |
| SQLServer: SSIS Pipeline xx.0: Flat buffer memory | The total amount of memory, in bytes, that all flat buffers use. Flat buffers are blocks of memory that a component uses to store data. A flat buffer is a large block of bytes that is accessed byte by byte. |
| SQLServer: SSIS Pipeline xx.0: Flat buffers in use | The number of flat buffers that the Data flow engine uses. All flat buffers are private buffers. |
| SQLServer: SSIS Pipeline xx.0: Private buffer memory | The total amount of memory in use by all private buffers. A buffer is not private if the data flow engine creates it to support data flow. A private buffer is a buffer that a transformation uses for temporary work only. For example, the Aggregation transformation uses private buffers to do its work. |
| SQLServer: SSIS Pipeline xx.0: Private buffers in use | The number of buffers that transformations use. |
| SQLServer: SSIS Pipeline xx.0: Rows read | The number of rows that a source produces. The number does not include rows read from reference tables by the Lookup transformation. |
| SQLServer: SSIS Pipeline xx.0: Rows written | The number of rows offered to a destination. The number does not reflect rows written to the destination data store. |
2.2. Les avantages de PerfMon
- Déjà installé sur les systèmes Windows (desktop et server). Il n’est donc pas nécessaire de l’installer.
- Il permet de monitorer non seulement des processus classiques mais aussi de remonter des métriques plus spécifiques sur SqlServer ou IIS.
- Il peut fonctionner en tant que service, sans qu’il ne soit nécessaire d’avoir une session ouverte. On peut donc laisser PerfMon collecter ses métriques pendant plusieurs jours et ainsi, surveiller l’évolution de l’exécution d’une application ou de la machine qui l’exécute.
- On peut exécuter PerfMon pour qu’il collecte des données sur une machine à distance.
2.3. Exécution de PerfMon
Le PerfMon est déjà installé : il est sur le : C:\WINDOWS\system32\perfmon.msc
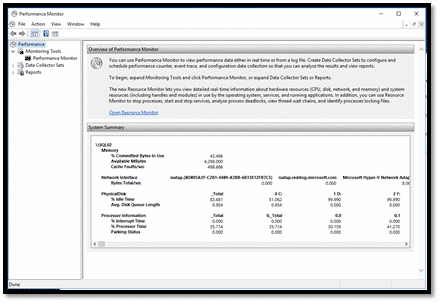
2.4. Configurer des collectes automatiques de données
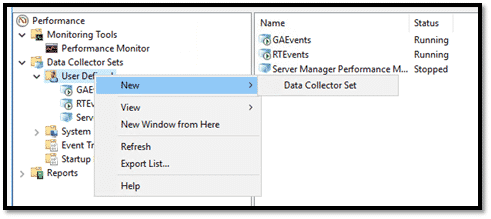
Sachant qu’on peut collecter les données en temps réel, cette procédure va détailler la collecte automatique des données. Pour effectuer des collectes automatiques, il faut :- Déplier « Data Collector Sets ».
- Déplier « User Defined ».
- Clic droit sur « User Defined » puis cliquer sur « Nouveau » et enfin sur « data Collector Set ».
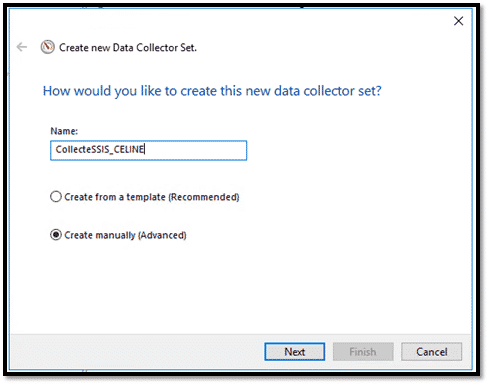
- Saisir le nom de Collector Set et Sélectionner « Create manually (advanced) » puis cliquer sur « Suivant ».
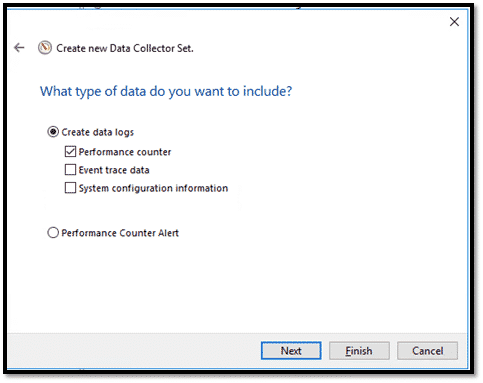
 Sélectionner « Performance Counter » puis cliquer sur « Suivant ».
Sélectionner « Performance Counter » puis cliquer sur « Suivant ».
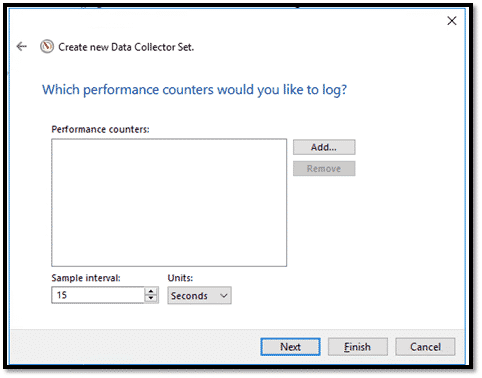 Cliquer sur « Add… » pour ajouter tous les compteurs de performance sur le chapitre 2.1.
Cliquer sur « Add… » pour ajouter tous les compteurs de performance sur le chapitre 2.1.
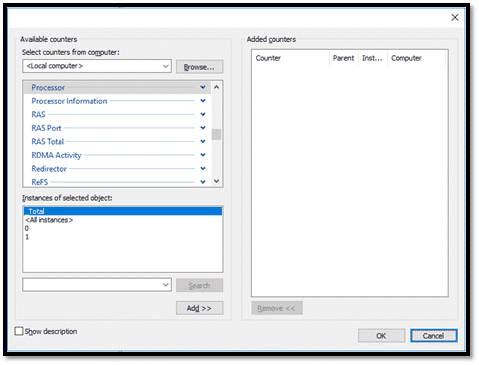
Sélectionner le compteur et Cliquer sur « Add>> ».
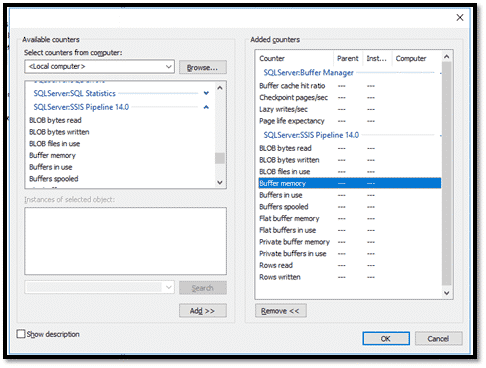 Cliquer sur « OK ».
Cliquer sur « OK ».
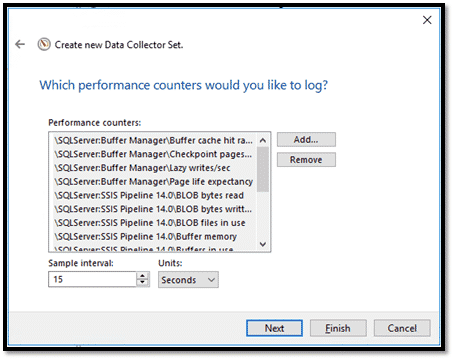 Cliquer ensuite sur « Finish ».
Cliquer ensuite sur « Finish ».
 Quand le Data Collector Sets est créé, on peut préciser quelques éléments de configuration supplémentaire :
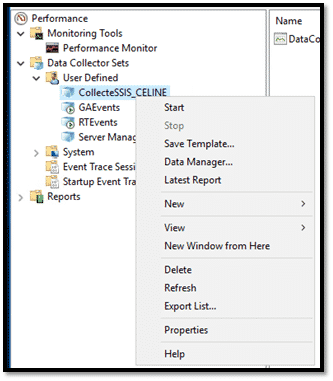
Clic droit sur le Data Collector Sets créé précédemment et cliquer sur « Properties ».
Quand le Data Collector Sets est créé, on peut préciser quelques éléments de configuration supplémentaire :
Clic droit sur le Data Collector Sets créé précédemment et cliquer sur « Properties ».
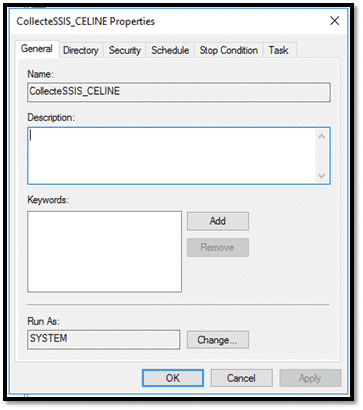 On peut personnaliser certains éléments :
On peut personnaliser certains éléments :
- Run As : l’utilisateur qui exécutera le compteur : ce paramétrage est particulièrement utile si l'on souhaite monitorer un processus lancé avec un utilisateur différent de celui qui effectue le paramétrage. Ce paramètre est disponible dans l’onglet « Général ».
- Root Directory : le répertoire dans lequel les fichiers des compteurs seront créés, accessible dans l’onglet « Directory ».
- Schedule : pour planifier la collecte, on peut spécifier la date et heure de début et de fin de collecte, accessible dans l’onglet « Schedule ».
- Stop condition : il peut être utile de paramétrer une condition d’arrêt pour éviter que la collecte s’effectue de façon permanente.
2.5. Démarrer un collecteur de données
Clic Droit sur le Collector et Cliquer sur « Start ». Une fois la collecte est démarrée, un triangle vert s’affiche.
Une fois la collecte est démarrée, un triangle vert s’affiche.
2.5.1 Programmer le démarrage d’une collecte
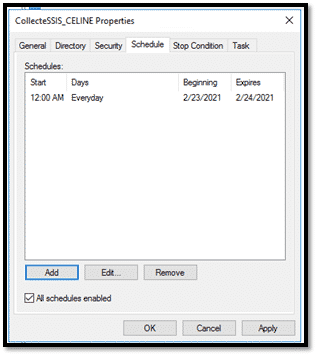
On peut programmer le démarrage et l’arrêt de la collecte sur les propriétés de la collecte et sur l’onglet « Schedule » en spécifiant la date de début et fin de la collecte.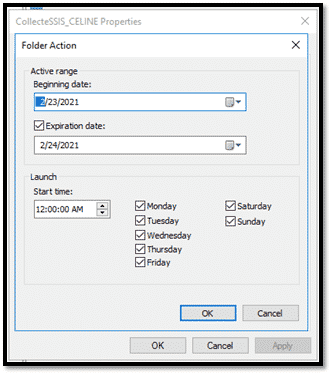
2.6. Lecture résultats d’une collecte
On peut lire la collecte en utilisant toujours le PerfMon, en cherchant le répertoire où la collecte est sauvegardée et double clic sur le fichier.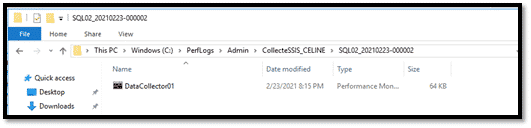
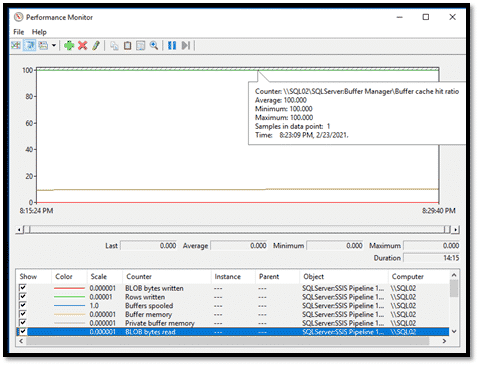
On peut aussi utiliser des outils tiers comme PAL par exemple.
Partage
