Amazon Redshift est l’offre Data Warehouse dans le Cloud d’AWS, qui permet un hébergement d’un volume important de données ( jusqu’à des Pétabytes) tout en garantissant de bonnes performances pour leur interrogation.
Des services de Data Warehouse sur le Cloud assez similaires sont Azure SQL WareHouse, Google Big Query, Snowflake (multi-Cloud).
Ils reposent tous sur une base de données orientée colonnes, avec du sharding des données et une architecture massivement parallèle pour les traitements.
Qu’est ce qu’une base de données orientée colonnes ?
Les Data Warehouse contiennent d’importants volumes de données, et les requêtes d’interrogation et de reporting sont très complexes. Les bases de données relationnelles classiques, avec un stockage des données en mode lignes, ont vite montré des limites de performance.
Les bases de données orientées colonnes vont stocker les données par colonne, chaque valeur d’une colonne sera stockée à la suite, permettant des facilités de compression et d’indexation, une charge IO moins importante et une lecture plus rapide des données.
Exemple en mode lignes
| RowID | Nom | Prénom | Age | Salaire |
| 1 | MARTIN | Kevin | 18 | |
| 2 | DURAND | Paul | 45 | 2000 |
| 3 | DUPOND | Paul | 50 | 3000 |
| 4 | MARTIN | Pierre | 3000 |
Ces données en mode orienté colonnes
| Nom | MARTIN:1 | DURAND;2 | DUPOND:3 | MARTIN:4 |
| Prénom | Kévin:1 | Paul:2 | Paul:3 | Pierre:4 |
| Age | 18:1 | 45:2 | 50:3 | |
| Salaire | 2000:2 | 3000:3 | 3000:4 |
Une bases de données orientés colonnes comme Redshift conserve les propriétés ACID d’une base de données relationnelles. Le langage SQL est également utilisé pour le requêtage.
Amazon RedShift
Redshift est un service Cloud managé, qui facilitera la construction et l’administration de votre entrepôt de données. L’installation peut se faire depuis la console, ou par les APIs (Aws Cli, SDKs).
Architecture
Nous parlerons d’un cluster Redshift, qui constitue le SGBD orienté colonnes, et qui va répartir ses données en de nombreux fichiers, stockés sur les nœuds du cluster.
Il s’appuie sur une architecture MPP (Massively Parallel Processing) :
- architecture shared nothing distribuée, et optimisée pour l’analytique.
- un leader node va orchestrer la répartition des données et gérer le méta modèle, préparer et répartir les requêtes en parallèle et agréger le résultat.
- des computes nodes qui vont stocker et processer les données : chaque compute node est partitionné en « slices », auxquelles sont allouées du disk et de la mémoire.
- ces nœuds sont des instances EC2 spécifiques optimisés en IO et au niveau du débit réseau.
- le storage est soit du disque SSD, instance DC2, pour une performance extrême, soit du disque magnétique, instance DS2, privilégiant une très forte volumétrie pour un prix réduit.
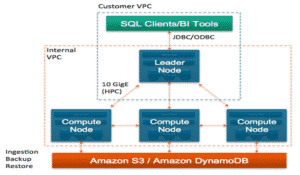
Pour du test, il est possible d’utiliser un cluster Redshift single-node, qui groupe les fonctions de leader node et d’un compute node dans une instance unique.
Design des données
Lors de la création des tables, il est possible soit de définir manuellement l’algorithme de compression à utiliser, soit laisser la commande COPY de chargement intial des données le choisir automatiquement (en fonction de l’analyse des données à charger).
Redshift possède 3 types de distribution des données :
- EVEN (défaut) : distribution en round-robin dans les slices
- KEY : utilise une distribution key, et un algorithme de hash de cette clé
- ALL : les données sont copiées sur le premier slice de chaque nœud
Il est également possible de définir des « sort keys », permettant le tri des données sur disque, assez similaire à un cluster index : les données sont ordonnées sur le disk et en mémoire, conservation des valeurs min et max pour chaque block de data (limite les IOs pour certaines requêtes).
Service managé
La charge d’administration technique est réduite, le service effectuant les actions de :
- monitoring et relance des composants du cluster en cas de crash
- sauvegarde automatique et en continue des nouvelles données sur Amazon S3
- intégration dans l’écosystème pour le monitoring, IAM, les outils d’intégration de données
- concurrency scaling : ajoute automatiquement de la capacité de cluster supplémentaire pour traiter une augmentation des requêtes de lectures simultanées. Cela prend en charge un nombre pratiquement illimité d’utilisateurs simultanés et de requêtes simultanées
Compatibilité SQL
AWS est parti d’une base de données PostgreSQL, et donc Redshift est compatible avec le langage SQL (mode PostgreSQL version 8.x) et c’est une base relationnelle (ACID).
Depuis Mai 2019, Redshift supporte également des procédures stockées, ce qui facilite le développement de traitements et les migrations depuis d’autres bases de données relationnelles.
Redshift Spectrum
Amazon Spectrum est une extension Data Lake de Redshift, permettant d’exécuter des requêtes SQL Amazon Redshift sur plusieurs exaoctets de données dans Amazon S3.
Pour améliorer les performances des requêtes et réduire les coûts, il est conseillé d’utiliser un format de données en colonnes, partitionné et compressé, tel que les formats Apache Parquet, ORC.
Pricing
Le pricing se fait sur le nombre de nœuds du cluster, qui dépend finalement du volume de données. Chaque type d’instance DC2, DS2 a un tarif à l’heure en fonction de la région.
La tarification peut être on-demand, ou avec une réservation d’instance sur un an ou 3 ans (discount jusqu’à 75%).
Il faut rajouter les charges :
- sur le storage des backups (aucun frais si ce volume est inférieur ou égal au volume total du cluster)
- les coûts de transferts des données
- éventuellement l’option Concurrency Scaling, permettant un scaling automatique lors de pics d’utilisation
Si cet aperçu des fonctionnalités de Redshift vous donne envie de mieux connaitre ce service, voici quelques ressources :
https://aws.amazon.com/fr/redshift/
https://www.youtube.com/watch?v=TJDtQom7SAA
https://www.youtube.com/watch?v=z2LxhuL54nM
Et si vous souhaitez vous former sur Amazon Web Services, découvrez notre offre de formations AWS.
