

Déployer une architecture MongoDB en Sharding
 Le 01/04/2020
Le 01/04/2020Non classé
 11 minutes de lecture
11 minutes de lectureSommaire
Sommaire
Partage





Déployer une architecture MongoDB en Sharding
CONTEXTE
Le sharding permet de partager ses données sur plusieurs instances. Il n'est donc plus nécessaire d'augmenter les ressources d'un serveur contenant la base de données mais plutôt d'ajouter un nouveau serveur qui contiendra une partie des données. Cette méthode est théoriquement moins coûteuse car l'on peut avoir une multitude de petits serveurs interconnectés plutôt qu'un ou deux gros serveurs très performants. Dans cette optique, nous allons répartir les données sur 3 serveurs distincts comme suit :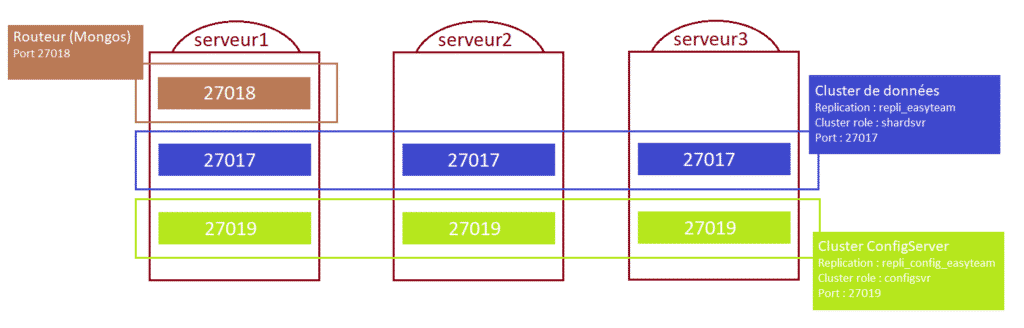
- Routeur (Mongos) : Le point d'entrée du client pour insérer ces données.
- Config Server : Contiendra les règles du sharding et sera répliqué.
- Données : Contiendra les données shardées.
INSTALLATION
Toutes les actions sont à effectuer sur tous les serveurs. Nous utiliserons ici la dernière version (4.2.3) sur CentOS 7.Création du fichier repository pour MongoDB
[root@serveurX]# echo "[mongodb-org-4.2] name=MongoDB Repository baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/4.2/x86_64/ gpgcheck=1 enabled=1 gpgkey=https://www.mongodb.org/static/pgp/server-4.2.asc" > /etc/yum.repos.d/mongodb-org-4.2.repo
Installation de MongoDB ainsi que toutes ses dépendances
[root@serveurX] yum install -y mongodb-org-4.2.3================================= Package ================================= Installation : mongodb-org Installation pour dépendances : mongodb-org-mongos mongodb-org-server mongodb-org-shell mongodb-org-tools ================================= Installation 1 Paquet (+4 Paquets en dépendance) Taille totale des téléchargements : 118 M Taille d'installation : 281 M
CONFIGURATION
Toutes les actions sont à effectuer sur tous les serveurs excepté la génération de la clef. Dans cet exemple, nous utiliserons l'architecture suivante :- Répertoire des données : /u01/mongodb/data
- Répertoire des logs : /var/log/mongodb
- Répertoire du configServer : /u01/mongodb/config
- Répertoire des PID : /var/run/mongodb
Création des répertoires
[root@serveurX]# mkdir -p /u01/mongodb/data [root@serveurX]# mkdir -p /u01/mongodb/config [root@serveurX]# mkdir -p /var/log/mongodb [root@serveurX]# mkdir -p /var/run/mongodb [root@serveurX]# chown -R mongod:mongod /u01 [root@serveurX]# chown -R mongod:mongod /var/log/mongodb [root@serveurX]# chown -R mongod:mongod /var/run/mongodb
Configurer le fichier hosts
[root@serveurX]# vi /etc/hosts @IP serveur1 @IP serveur2 @IP serveur3
Création d'une clef d'authentification
Cette clef n'est à générer qu'une seule fois puis à transférer sur les autres serveurs. A noter qu'en production, il est préférable d'utiliser une clef x.509. Nous n'utiliserons cette clef qu'à la fin de l'installation.[root@serveur1]# openssl rand -base64 756 > /u01/mongodb/easyteam.key [root@serveur1]# chmod 400 /u01/mongodb/easyteam.key [root@serveur1]# chown mongod:mongod /u01/mongodb/easyteam.key[root@serveur1]# scp /u01/mongodb/easyteam.key mongod@serveurX:/u01/mongodb/easyteam.key
Vérifier les paramètres réseaux
TOules les instances doivent être capables de communiquer entre-elles et la vérification du pare-feu, du proxy et du selinux est très importante. Ci-dessous, un exemple de commandes à passer pour autoriser MongoDB à lire les fichiers si le selinux doit obligatoirement être en enforcing :[root@serveurX]# yum install -y checkpolicy [root@serveurX]# yum install -y policycoreutils-python[root@serveurX]# semanage fcontext -a -t mongod_var_run_t /u01/mongodb.* [root@serveurX]# semanage fcontext -a -t mongod_var_lib_t /u01/mongodb/data.* [root@serveurX]# semanage fcontext -a -t mongod_log_t /var/log/mongodb/log.* [root@serveurX]# semanage fcontext -a -t mongod_var_run_t /var/run/mongodb.* [root@serveurX]# chcon -Rv -u system_u -t mongod_var_run_t /u01/mongodb [root@serveurX]# chcon -Rv -u system_u -t mongod_var_lib_t /u01/mongodb/data [root@serveurX]# chcon -Rv -u system_u -t mongod_log_t /var/log/mongodb [root@serveurX]# chcon -Rv -u system_u -t mongod_var_run_t /var/run/mongodb [root@serveurX]# restorecon -R -v /u01/mongodb [root@serveurX]# restorecon -R -v /u01/mongodb/data [root@serveurX]# restorecon -R -v /var/log/mongodb [root@serveurX]# restorecon -R -v /var/run/mongodb
MISE EN PLACE DU CONFIG SERVER
Toutes les actions sont à effectuer sur tous les serveurs. Il va nous falloir un fichier de configuration pour chaque instance mais comme il faut bien commencer quelque part, on va débuter par le config server.Fichier de configuration
En bleu les modifications à apporter au fichier de configuration.- systemLog.path : Répertoire de la log
- storage.dbPath : Répertoire de stockage des données
- processManagement.pidFilePath : Localisation du fichier PID
- net.port : Le port du cluster
- net.binIp : Hostname sur lequel écouter pour les connexions clientes (soit même)
- net.bindIP : 0.0.0.0 (permet de tout accepter)
- net.binIpAll : true (permet également de tout accepter)
- security.keyFile : Localisation de la clef (non utilisé pour le moment)
- replication.replSetName : Nom de la réplication de ce cluster
- sharding.clusterRole : Rôle de ce cluster dans la mise en place du sharding
[root@serveurX]# cp /etc/mongod.conf /etc/mongod_config.conf [root@serveurX]# vi /etc/mongod_config.conf[...] systemLog: destination: file logAppend: true path: /var/log/mongodb/mongod_config.log [...] storage: dbPath: /u01/mongodb/config journal: enabled: true [...] processManagement: fork: true pidFilePath: /var/run/mongodb/mongod_config.pid timeZoneInfo: /usr/share/zoneinfo [...] net: port: 27019 bindIp: serveurX [...] #security: #keyFile: /u01/mongodb/easyteam.key [...] replication: replSetName: repli_config_easyteam [...] sharding: clusterRole: configsvr Remarque A l'inverse du sharding, où les données sont partitionnées, la réplication permet d'avoir les mêmes données copiées sur plusieurs instances.
Modifier le fichier d'initialisation
Cette étape permet de modifier le fichier utilisé par systemctl pour avoir les bonnes informations concernant l'arrêt/relance du process mongod_config[root@serveurX]# cp /usr/lib/systemd/system/mongod.service /usr/lib/systemd/system/mongod_config.service [root@serveurX]# sed -i 's#/etc/mongod.conf#/etc/mongod_config.conf#g' /usr/lib/systemd/system/mongod_config.service [root@serveurX]# sed -i 's#/var/run/mongodb/mongod.pid#/var/run/mongodb/mongod_config.pid#g' /usr/lib/systemd/system/mongod_config.service[root@serveurX]# systemctl daemon-reload
INITIALISATION
Démarrer le cluster sur les 3 nœuds
[root@serveurX]# systemctl start mongod_config [root@serveurX]# systemctl enable mongodA partir de maintenant, vous devez pouvoir être capable de vous connecter sur chacune de vos instances depuis n'importe quel serveur. Si ce n'est pas le cas, vérifiez tous vos paramètres réseaux.
[root@serveur1]# mongo --host serveur1 --port 27019 [root@serveur1]# mongo --host serveur2 --port 27019 [root@serveur1]# mongo --host serveur3 --port 27019
Mise en place de la réplication
Action à effectuer sur un seul serveur. Maintenant que nous pouvons accéder à toutes les instances, il faut ajouter toutes les membres à la réplication que nous avons définie dans le fichier de configuration. Le heartbeat intégré au cluster va vérifier toutes les 10 secondes, par défaut, l'état des instances et élire celle disponible qui a la plus grosse priorité, en tant que Primaire. Une instance Primaire recevra toutes les informations clientes et répliquera sur les Secondaires. Ci-dessous un rapide exemple du fonctionnement de la réplication et de l'heartbeat.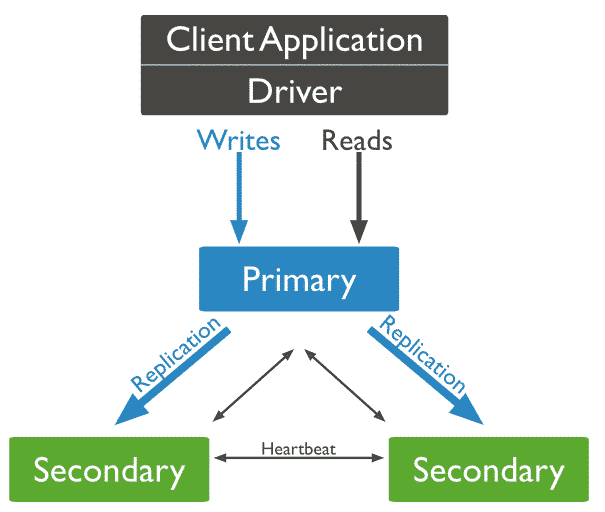 Et si le noeud Primaire tombe :
Et si le noeud Primaire tombe :
 Un autre point, est l'ajout de la priorité que j'ai définie arbitrairement sur 3, 2 puis 1. Le but étant de prioriser l'instance sur le serveur1 en tant que Primaire.
Initialisation de la réplication :
Un autre point, est l'ajout de la priorité que j'ai définie arbitrairement sur 3, 2 puis 1. Le but étant de prioriser l'instance sur le serveur1 en tant que Primaire.
Initialisation de la réplication :
[root@serveur1]# mongo --host serveur1 --port 27019> rs.initiate( { _id: "repli_config_easyteam", configsvr: true, members: [ { _id : 0, host : "serveur1:27019", priority : 3 }, { _id : 1, host : "serveur2:27019", priority : 2 }, { _id : 2, host : "serveur3:27019", priority : 1 } ] } )
Vérifier la mise en place de la réplication
repli_config_easyteam:PRIMARY>rs.status()
MISE EN PLACE DU CLUSTER DE DONNEES
Maintenant que nous avons notre premier cluster de configuré sur le port 27019, il faut effectuer la même chose pour le port 27017 qui servira à stocker les données shardés. Toutes les actions sont à effectuer sur tous les serveurs.Fichier de configuration
[root@serveurX]# vi /etc/mongod.conf[...] systemLog: destination: file logAppend: true path: /var/log/mongodb/mongod.log [...] storage: dbPath: /u01/mongodb/data journal: enabled: true [...] processManagement: fork: true pidFilePath: /var/run/mongodb/mongod.pid timeZoneInfo: /usr/share/zoneinfo [...] net: port: 27017 bindIp: serveurX [...] #security: # keyFile: /u01/mongodb/easyteam.key [...] replication: replSetName: repli_easyteam [...] sharding: clusterRole: shardsvr
INITIALISATION
Démarrer le cluster de données sur les 3 nœuds
Il n'y a pas besoin de modifier le fichier utilisé par systemctl car nous gardons les paramètres par défaut du fichier de conf et PID.[root@serveurX]# systemctl start mongod [root@serveurX]# systemctl enable mongod
Mise en place de la réplication
Action à effectuer sur un seul serveur.[root@serveur1]# mongo --host serveur1 --port 27017> rs.initiate( { _id: "repli_easyteam", members: [ { _id : 0, host : "serveur1:27017", priority: 3 }, { _id : 1, host : "serveur2:27017", priority: 2 }, { _id : 2, host : "serveur3:27017", priority: 1 } ] } )
Vérifier la mise en place de la réplication
repli_easyteam:PRIMARY>rs.status()
MISE EN PLACE DU SHARDING
Avant de commencer cette étape, il faut sécuriser la connexion entre chaque nœud du cluster avec une clef. Une fois cette association effectuée, il faudra obligatoirement se connecter avec un utilisateur pour effectuer des actions.Création des utilisateurs
Dans cet exemple, nous allons créer un SuperUtilisateur (root) et un administrateur (admin) qui pourra effectuer des actions sur toutes les bases. La création des utilisateurs s'effectue sur une base associée. Dans notre cas ce sera la database admin (créée par défaut).[root@serveur1]# mongo --host serveur1 --port 27017
repli_easyteam:PRIMARY> use admin
repli_easyteam:PRIMARY> db.createUser({user: "root",pwd: "root",roles: [ { role: "root", db: "admin" } ]})
repli_easyteam:PRIMARY> db.createUser({user: "admin",pwd: "admin",roles: [ { role: "userAdminAnyDatabase", db: "admin" } ]})
[root@serveur1]# mongo --host serveur1 --port 27019
repli_easyteam:PRIMARY> use admin
repli_easyteam:PRIMARY> db.createUser({user: "root",pwd: "root",roles: [ { role: "root", db: "admin" } ]})
repli_easyteam:PRIMARY> db.createUser({user: "admin",pwd: "admin",roles: [ { role: "userAdminAnyDatabase", db: "admin" } ]})
Remarque
Nous avons 2 clusters répliqués, les actions sont donc à effectuer sur chaque cluster pour plus de cohérence.
Mise en place de la clef
La clef étant déjà générée et prête à l'emploi, il ne reste plus qu'à décommenter la partie sécurité dans tous les fichiers de conf et de redémarrer tout le cluster.[root@serveurX]# vi /etc/mongod*.conf [...] security: keyFile: /u01/mongodb/easyteam.key [...][root@serveurX]# systemctl restart mongod [root@serveurX]# systemctl restart mongod_config
Vérification
Vous pouvez tenter d'afficher les databases avec connexion utilisateur et sans pour vérifier que tout fonctionne.[root@serveur1]# mongo --host serveur1 --port 27019 repli_config_easyteam:PRIMARY> show dbs[root@serveur1]# mongo --host serveur1 --port 27019 -u "root" -p "root" repli_config_easyteam:PRIMARY> show dbs admin 0.000GB config 0.000GB local 0.000GB
Initialisation de Mongos
Mongos est considéré comme étant le point d'entrée des connexions clientes et fonctionne comme un routeur. On va le configurer pour le connecter à notre ConfigServer (qui contiendra la configuration de notre sharding) puis l'initialiser avec notre cluster de données répliqué. Mongos ne nécessite pas de répertoire de données.[root@serveur1]# cp /etc/mongod.conf /etc/mongos.conf[...] systemLog: destination: file logAppend: true path: /var/log/mongodb/mongos.log [...] > Supprimer le paragraphe data [...] processManagement: fork: true pidFilePath: /var/run/mongodb/mongos.pid timeZoneInfo: /usr/share/zoneinfo [...] net: port: 27018 bindIpAll: true [...] security: keyFile: /u01/mongodb/easyteam.key [...] > Supprimer la partie replication [...] sharding: configDB: repli_config_easyteam/serveur1:27019,serveur2:27019,serveur3:27019
Démarrer mongos
[root@serveur1]# mongos --config /etc/mongos.conf
Création d'un shard
Toute la configuration du sharding s'effectue via Mongos en étant connecté avec un utilisateur possédant à minima le rôle de ClusterManager. Dans cet exemple, nous allons créer notre premier shard en se basant sur notre cluster répliqué de données : repli_easyteam.[root@serveur1]# mongo --host serveur1 --port 27018 -u "root" -p "root"
mongos> sh.addShard("repli_easyteam/serveur1:27017,serveur2:27017,serveur3:27017")
Vérification
mongos> sh.status()--- Sharding Status --- sharding version: { "_id" : 1, "minCompatibleVersion" : 5, "currentVersion" : 6, "clusterId" : ObjectId("5e6b9c3b91f427b716442b11") } shards: { "_id" : "repli_easyteam", "host" : "repli_easyteam/serveur1:27017,serveur2:27017,serveur3:27017", "state" : 1 } active mongoses: "4.2.3" : 1 autosplit: Currently enabled: yes balancer: Currently enabled: yes Currently running: no Failed balancer rounds in last 5 attempts: 0 Migration Results for the last 24 hours: No recent migrations databases: { "_id" : "config", "primary" : "config", "partitioned" : true } Il ne reste plus qu'à définir des règles de sharding en fonction de vos données, mais actuellement votre architecture mongoDB est fonctionnelle.
Partage
