Un bref aperçu du contexte Apache Kafka…
Tout commence en 2009. En travaillant sur un projet Big Data d’adoption Hadoop ,une équipe de LinkedIn s’est confrontée à des problèmes d’intégration des données en provenance des différents systèmes de l’entreprise. Ainsi, ils ont commencé à développer un système qui sera scalable et qui supportera des débits très importants des flux de données en provenance des différents systèmes de l’entreprise pour la publication ou la lecture. C’est ainsi qu’est né Apache Kafka (écrit en Scala et Java), un système de messagerie distribuée en mode publish-subscribe. Et dès 2011, la technologie a été remise à la communauté open-source sous la forme d’un système de messagerie hautement évolutif.
Les données et les logs utilisés par les systèmes complexes d’aujourd’hui doivent être traités, retraités, analysés et manipulés, souvent en temps réel. C’est pourquoi Apache Kafka joue un rôle important dans le domaine de la diffusion de messages en streaming .
Les principes de conception clés de Kafka ont été élaborés en fonction du besoin croissant d’architectures à haut débit facilement évolutives et permettant de stocker, de traiter et de retraiter des streams. Il s’agit aujourd’hui d’une plateforme centralisée pour le stockage et l’échange en temps réel de toutes les données émises par les entreprises qui l’utilisent. De nombreuses entreprises l’ont adopté, à tel point que Kafka est aujourd’hui considéré comme une plateforme standard pour les pipelines de traitement de données.
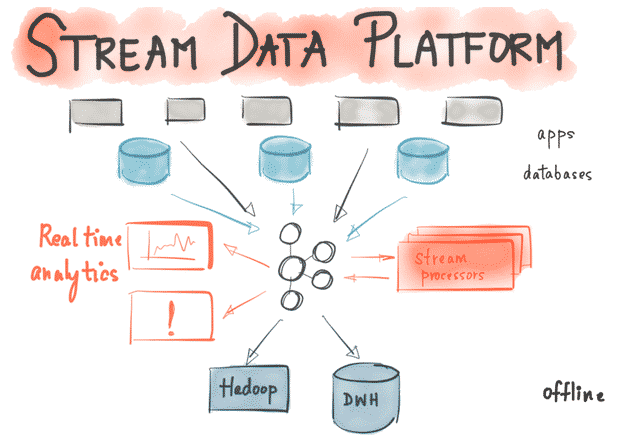
Fonctionnement du Système
Apache Kafka est un logiciel qui permet de définir des Topics (considérez un Topic comme une catégorie de donnée), d’ajouter des applications, de traiter et de retraiter des enregistrements .
Les applications se connectent à ce système et transfèrent un message sur le Topic. Un message peut contenir n’importe quel type d’information, par exemple, des informations sur un événement qui s’est produit sur un site web, ou un événement qui est censé déclencher un événement. Une autre application peut se connecter au système et traiter ou retraiter les messages d’un topic . Les données envoyées sont conservées jusqu’à l’expiration d’une période de conservation déterminée (configurable).
Les enregistrements sont des tableaux d’octets qui peuvent stocker n’importe quel objet dans n’importe quel format. Un message (ou enregistrement) a quatre attributs, la ‘key’ et la ‘value’ qui sont obligatoires, les ‘timestamp’ et ‘headers’ qui sont facultatifs. La valeur peut être tout ce qui doit être envoyé, par exemple, du JSON ou du texte.
Les quatre parties principales d’un système Kafka :
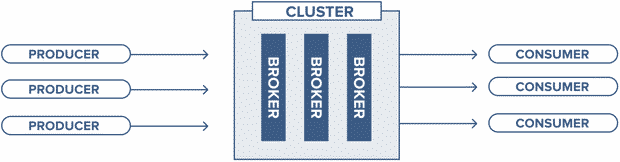
- Broker : Traite toutes les demandes des clients (production, consommation et métadonnées) et conserve les données répliquées dans le cluster. Il peut y avoir un ou plusieurs brokers dans un cluster (tous les enregistrements Kafka sont organisés dans des topics).
- Zookeeper : Conserve l’état du cluster (Brokers, Topics, Utilisateurs).
- Producer : Envoie les enregistrements à un broker (écrit sur des topics).
- Consumer : Consomme les messages en provenant du broker (extrait des enregistrements d’un topic) .
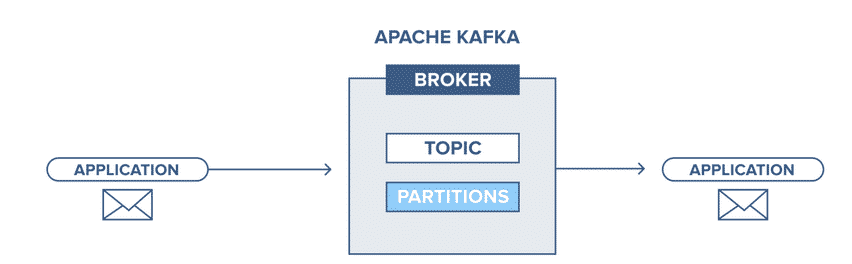
Broker et Topic Kafka
Broker Kafka
Un cluster Kafka est constitué d’un ou de plusieurs serveurs (broker Kafka) fonctionnant sous Kafka.
Il est possible de faire fonctionner un seul broker Kafka, mais cela ne donne pas tous les avantages que Kafka dans un cluster peut donner, par exemple, la réplication des données.
La gestion des brokers du cluster est assurée par le Zookeeper et il peut y avoir plusieurs Zookeepers dans un cluster (de préférence de trois à cinq, en gardant un nombre impair).
Topic Kafka/Partitions
Un Topic est une « catégorie » (similaire à une table dans une base de données sans les contraintes) dans lequel les messages sont stockés et publiés.
Kafka conserve les enregistrements dans le log, ce qui rend les consommateurs responsables du suivi de la position dans le log, connu sous le nom de « l’offset ».
Généralement, un consommateur avance l’offset de manière linéaire au fur et à mesure de la lecture des messages. Cependant, la position est en fait contrôlée par le consommateur, qui peut consommer les messages dans n’importe quel ordre. Par exemple, un consommateur peut revenir à un offset plus ancien lors du retraitement des enregistrements.
Les Topics sont divisés en partitions :
- Chaque partition est ordonnée.
- Chaque message à l’intérieur d’une partition reçoit un offset (un id incrémentiel).
- Un offset n’a de sens que pour une partition spécifique (l’offset 2 dans la partition 1 ne représente pas les mêmes données que l’offset 2 de la partition 2).
- L’ordre n’est garanti que dans le cadre d’une partition (Les offsets sont indépendants).
- Les données ne sont conservées que pour une durée limitée (2 semaines par défaut).
- Une fois que les données sont écrites sur une partition, elles ne peuvent plus être modifiées (il faut utiliser l’offset suivant pour l’update).
- Les données sont affectées de manière aléatoire à une partition, à moins qu’une clé ne soit fournie (tous les enregistrements ayant la même clé arriveront sur la même partition).
- Vous pouvez avoir autant de partitions par topic que vous le souhaitez.
- Les consommateurs peuvent lire les messages à partir d’un offset spécifique et sont autorisés à lire à partir de n’importe quel point d’offset qu’ils choisissent. Cela leur permet de rejoindre le cluster à tout moment.
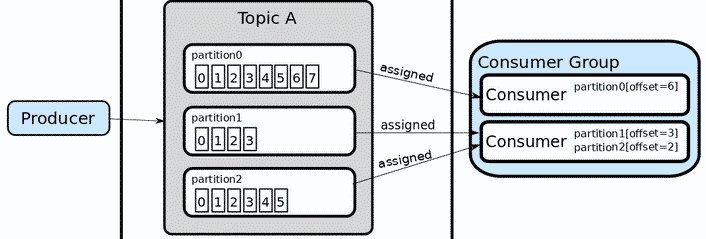
Exemple :
Nous avons un broker avec trois topics , où chaque topic a 8 partitions, le producteur envoie un enregistrement à la partition 1 du topic 1 et comme la partition est vide, l’enregistrement se retrouvera à l’offset 0, le prochain enregistrement ajouté à la partition 1 sera à l’offset 1, et le 3ème à l’offset 2, et ainsi de suite… C’est ce que l’on appelle un log de commit et il n’y a aucun moyen de modifier les enregistrements existants dans le log. C’est également le même offset que le consommateur utilise pour préciser où commencer la lecture.
NB : Dans Kafka, la réplication est mise en œuvre au niveau de la partition. L’unité redondante d’une partition est appelée « replica ». Chaque partition a généralement une ou plusieurs répliques, ce qui signifie que les partitions contiennent des messages qui sont répliqués sur quelques brokers Kafka dans le cluster.

1 réflexion sur “Kafka pour les débutants”
Ping : Master Note Middleware 2020 - EASYTEAM
Les commentaires sont fermés.