1- Qu’est-ce que Cosmos DB ?
Cosmos DB est une solution Azure PaaS (Plateform As A Service) positionnée en tant que base de données (DaaS : Database As A Service), tout comme Azure SQL Database, Azure Database for PostgreSQL, Azure Database for MySQL, SQL DataWarehouse, …
Contrairement à ces bases de données relationnelles traditionnelles, Cosmos DB est une base de données distribuée NoSQL, donc non relationnelle, haut débit, faible latence, multi-modèles, scalable en quelques minutes.
Sur le Portail Azure, Cosmos DB est dans la catégorie de services « Databases » :
Figure 1. Azure Cosmos DB dans Azure
La base Cosmos DB ne peut pas être installée sur un poste de travail comme SQL Server ou autre SGBD, elle est dédiée Azure. Tout est géré par Microsoft de façon transparente pour l’utilisateur, Microsoft assure un SLA de service à 99,999%.
Cette base est distribuée au niveau mondial (possibilité de distribuer les données entre plusieurs serveurs en utilisant une clé de partition) et donc disponible dans toutes les régions Azure du monde. Elle peut aussi être répliquée (possibilité de répliquer les mêmes données dans différentes régions) ce qui permet d’avoir les données répliquées dans différentes régions selon notre souhait et besoin, cela peut être très pratique pour une application internationale par exemple.
On assure la haute disponibilité en choisissant une ou des réplications comme base de secours si un désastre se produit, en mettant la base de secours comme base principale.
Dans Cosmos DB, on peut définir une seule région d’écriture et les autres en lecture, comme on peut spécifier plusieurs régions d’écriture et de lecture.
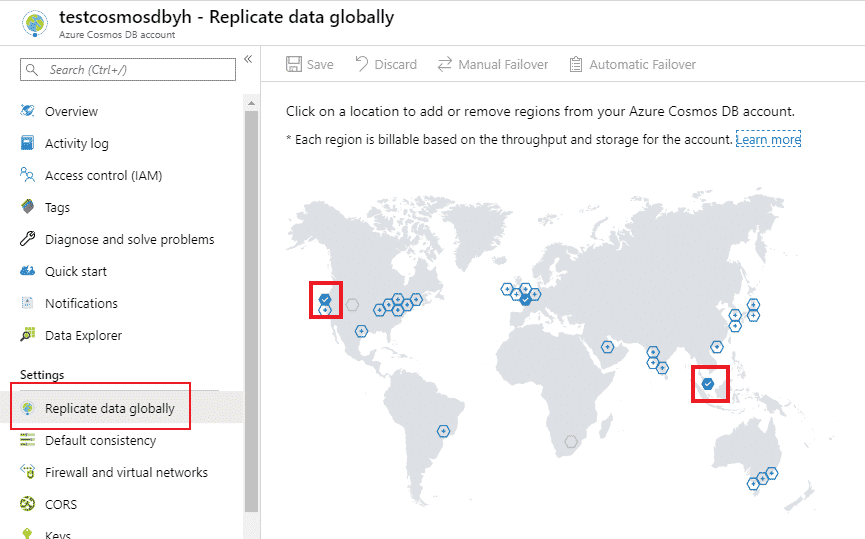
Figure 2. Aperçu des réplications de bases Cosmos DB
2- Distribution des données dans Cosmos DB : Partitionnement
Cosmos DB est une base très importante pour Microsoft de par sa distribution/réplication au niveau mondial. Cette distribution des données se fait en utilisant une clé de partitionnement (Partition Key) définie par les utilisateurs. Elle est très importante et doit être choisie soigneusement pour garantir une distribution équilibrée sur les différentes partitions et par conséquent des performances au requêtage.
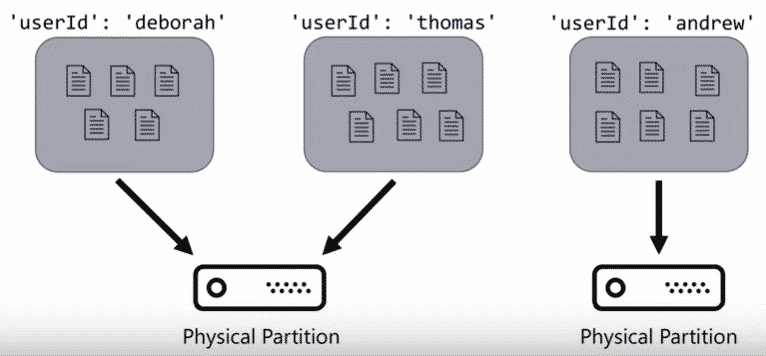
Figure 3. Mécanique de partitionnement dans Cosmos DB
On répartit les documents en suivant la clé de partition sur des partitions logiques, sachant qu’une ou plusieurs partitions logiques sont stockées dans une partition physique dans des serveurs physiques pour la scalabilité horizontale.
Si à un moment, la taille des partitions logiques devient trop importante, un serveur physique est rajouté et une redistribution complète des partitions sur ce pool de serveurs est réalisée.
Un bon choix de partitions est d’attendre un bon niveau de distribution, égale en termes de stockage et de débit/ d’accès (répartir les différentes requêtes sur les différentes partitions).
Si par exemple, je mets la clé de partition dans la clause where (filtre sur la clé de partition), la réponse est très rapide. Si j’utilise en revanche une donnée qui n’est pas la clé de partition dans la clause where, alors la requête est distribuée sur tous les serveurs, elle consommera donc plus de temps et de ressources (CPU, IOPs, …).
On peut optimiser les performances des requêtes en revoyant la clé de partition ou bien en créant des clés composées.
3- Cohérence / Consistance
Un des avantages de la réplication de la base Cosmos DB dans des régions du monde entier est l’utilisation des applications de ces régions des bases correspondantes. Ceci offre une proximité, certes, mais qu’en est-il de la cohérence de données et de la consistance ?
Si je mets à jour ma base de données en Europe, qu’une personne la consulte en Australie, elle n’aura pas la mise à jour tout de suite.
Cosmos DB offre 5 niveaux de cohérences de données paramétrable via l’option « Default Consistency » de Cosmos DB.
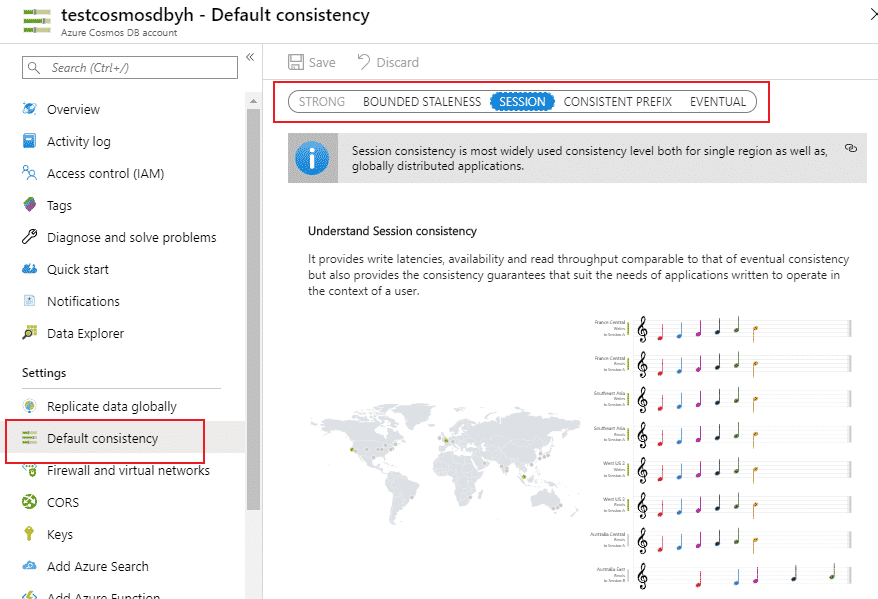
Figure 4. Options de consistance de données dans Cosmos DB
Via cette option, nous pouvons définir le niveau de latence qu’on pourrait accepter pour notre base de données et donc la mise à jour des données. Il n’y a pas de consistance parfaite, mais toujours des compromis. Azure Cosmos DB offre 5 modèles de consistance qui permettent de choisir selon ce qui est important pour vous et ce que vous pouvez sacrifier. Explorons-les dans le tableau ci-dessous :
| Option Consistency | Description |
Strong (Forte) | Si je souhaite une cohérence forte, je ne peux travailler que sur 2 régions. Dès que j’en ai plus, l’option « STRONG » n’est plus disponible. J’ai la garantie de toujours avoir la dernière version de la donnée. |
| Bounded Staleness (Obsolescence limitée) | J’ai la garantie que mes lectures ne seront pas plus obsolètes que : – un décalage max d’opérations (pour une seule région 10 < max lag < 1 000 000 et pour multi région 100 000 < max lag < 1 000 000), – un décalage max de temps (5 sec < max lag < 1 jour pour une ou plusieurs régions). S’applique sur plusieurs régions.
|
| Session | Garantie d’avoir des données cohérentes sur ma session à moi, voir mes écritures dans ma session. Si je me connecte avec une autre session, je n’ai pas la garantie de voir les modifications faites par moi. C’est le niveau de consistance standard, il offre une garantie de mise à jour des données et un meilleur débit. |
Consistent Prefix (préfixé cohérent) | J’ai une garantie de l’ordre de lecture (je lis les données par ordre d’arrivée/ d’écriture sur la base). |
Eventual (faible) | Pas de garantie que les lectures soient cohérentes mais on a des gains de rapidité en écriture. Basiquement, c’est comme une synchronisation asynchrone. Ça garantit que les changements seront répliqués éventuellement et avec la plus petite latence car pas besoin d’attendre des commit. |
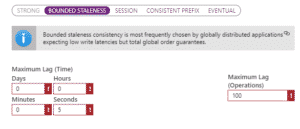
Tableau 1. Options de consistances dans Cosmos DB
4- Types de données dans Cosmos DB
Cosmos DB offre différents modèles de base de données avec le même moteur.
Au niveau le plus fin, Azure Cosmos DB stocke les données en format ARS (Atom-Record-Sequence), il traduit tous les modèles de données en modèles atome-record-sequence. Donc, tout devient atome, record ou séquence.
Les données sont ensuite projetées comme des APIs, qu’on spécifie lors de la création de la base. Au moment où l’article est rédigé, Azure Cosmos DB supporte 4 types de modèles :
- Key value pairs
- Column family
- Document
- Graph

Figure 5. Types de données stockées dans Cosmos DB
5- Type d’APIs supportées par Azure Cosmos DB
Azure Cosmos DB supporte plusieurs APIs qui peuvent communiquer avec toutes les données en fonction du modèle utilisé, les développeurs peuvent donc développer avec leur techno préférée.
Actuellement, je peux déployer ma base Cosmos DB en utilisant ces 5 modèles d’API :
| Type API | Description | Requêtage |
API Core (SQL)
| API historique, avant Cosmos DB, il y avait Document DB. Stocke les données sous format JSON. Chaque document est l’équivalent d’une ligne dans une table SQL. Chaque attribut du JSON correspond à un champ SQL. Structure plus riche avec listes et hiérarchies. | Langage proche du SQL |
API Mongo DB
| Proche de l’API SQL. Stocke les données sous format JSON. Peut être considéré comme un mode de compatibilité avec MongoDB et les SDK MongoDB. Si vous avez déjà des projets MongoDB, Cosmos DB peut servir d’équivalent PaaS MongoDB dans Azure. | Avec les APIs MongoDB |
API Cassandra
| Stocke les données en clé-valeur. Si je souhaite migrer mes bases Cassandra de IaaS en PaaS, Cosmos DB est l’équivalent dans Azure. | CQL (Cassandra Query language) |
API table
| Technologie de Azure Storage table (mode table). Stockage des données en clé-valeur. | Requêtes OData, LINQ dans le code REST API d’origine pour les opérations GET |
API Gremlin
| Orienté graphe. Stockage des objets en type graphes : vertex, nœuds, entités, relations entre les nœuds (Edge), et des propriétés qu’on peut rajouter sur les nœuds et les Edges. | Compatible avec les langages Graph tel que Apache Tinkerpop |


Tableau 2. Différentes APIs dans Cosmos DB
Comment choisir la bonne API ?
Si j’ai déjà un projet MongoDB, Cassandra, Table Azure ou Gremlin à migrer, alors j’utilise les APIs correspondantes.
Si j’ai des analyses de relations entre les données, j’utilise l’API Gremlin qui utilise les bases Graph et qui sont les seules à pouvoir analyser ce besoin.
Sinon, j’utilise l’API fournit par défaut par Microsoft qui est API SQL qui peut être utilisées dans tous les scénarios.
6- Composants de la base Cosmos DB
Dans Azure, on crée d’abord un compte base de données Cosmos DB dans lequel on peut créer plusieurs bases de données Cosmos DB.
Pour chaque base Cosmos DB, on a besoin de créer un ou plusieurs conteneurs, à l’intérieur desquels on crée des Items.
Les conteneurs/items dépendent de l’API choisi au préalable pour la base.
Voici un aperçu de l’organisation d’une base Cosmos DB dans Azure :
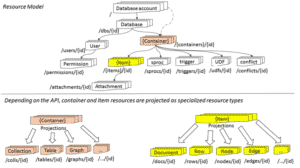
Figure 6. Modèle Cosmos DB dans Azure
Voici les différents container/items selon l’API utilisée dans Cosmos DB :
| Azure CosmosDB Entité | Core (SQL) API | MongoDB API | Cassandra API | Table API | Gremlin API |
| Container | Collection | Collection | Table | Table | Graph |
| Item | Document | Document | Partitionned Row | Item | Node or Edge |
Tableau 3. Conteneurs/Items dans Cosmos DB selon API choisie
7- Quelques fonctionnalités Cosmos DB
- Indexation automatique des données et donc optimisation de ces dernières.
- TTL (Time To Live) : permet de définir une date de suppression automatique d’un document après un certain temps. Par exemple sur les données streaming, je n’ai besoin de les garder qu’un mois ou deux, données glissantes sur 2 mois, au bout de deux mois ça se supprime tout seul.
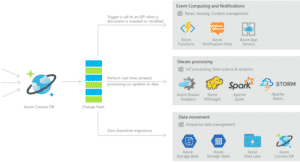
- Change Feed : c’est une API exposée par tous les conteneurs Cosmos DB, c’est une API à laquelle on peut souscrire pour être notifié à chaque fois qu’un changement se produit (création ou mise à jour de document) et s’en servir selon le besoin. Le change feed peut être consommé par le service Azure Functions ou n’importe quel code utilisant les SDKs cosmos DB.
Il permet par exemple de configurer un trigger sur une mise à jour de données sur chaque document (rajout d’un client) de déclencher actions (une mise à jour dans l’application, …).
8- Tarification Cosmos DB
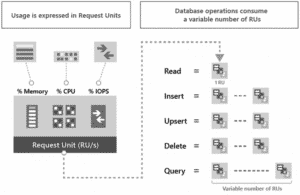
La tarification Azure est par unités de RU (Request Unit/s) et par Stockage par mois. Les RUs sont calculés en fonction de la consommation en CPU/RAM/IOPS des requêtes.
Lecture d’un item (document) de 1 Ko =1 RU
Ecriture d’un item de 1 Ko = 5 RU (en général car ça peut dépendre des propriétés du document)
Requête = cela dépend du nombre de documents, de la volumétrie des données à parcourir, de la complexité de la requête, du nombre de résultats à renvoyer.
Les quotas de RU sont provisionnés au niveau conteneur ou base de données.
Chaque requête traitée par Cosmos DB consomme des RUs. Si l’ensemble des requêtes dépassent le quota RU approvisionné, alors la ressource envoie un message d’erreur, ce qui implique de la latence.
On peut le changer en programmant via des appels API ou SDK (exemple des business qui utilisent Cosmos DB le jour donc plus de RU le jour et moins la nuit via 2 appels d’API, un le matin et un le soir, pour approvisionner au mieux le nombre d’API).
9- Implémentation
Après avoir défini les éléments essentiels d’une base Cosmos DB, voyons voir ce que ça donne en pratique :
 | Depuis le portail Azure, parcourir tous les services DataBase et choisir Cosmos DB ou bien rechercher Cosmos DB directement dans la barre de recherche. |
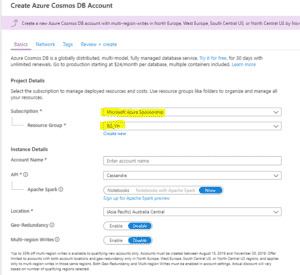 | Choisir la souscription Azure (une souscription gratuite de 30 jours est possible). Choisir le groupe de ressources ou le créer. Un groupe de ressources est un container logique de différents services Azure que je souhaite regrouper pour une besoin métier ou projet. |
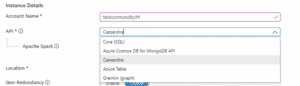 | Renseigner le nom du compte Cosmos DB que je vais créer. Renseigner le modèle d’API à utiliser avec ce compte parmi les 5 disponibles. |
| Je peux également activer Apache Spark avec ce compte pour utiliser des Notebooks, mais je ne vais pas détailler ce point, je mets None. | |
Spécifier la région où stocker le compte. Si je souhaite une géo redondance du compte sur plusieurs régions. Si j’autorise plusieurs régions d’écriture. | |
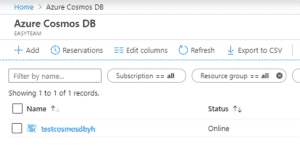 | Une fois la base de données créée, je peux la consulter via le service Azure Cosmos DB. Pour l’instant ma base est vide. |
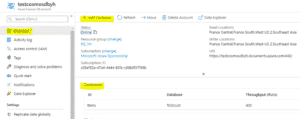 | Dans la base Cosmos DB, pour commencer à l’utiliser, on crée un ou plusieurs containers (conteneurs). |
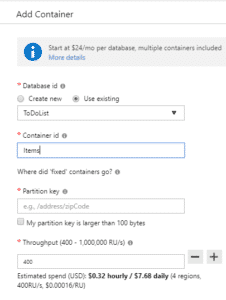
| Pour chaque Container rajouté, il faudra spécifier : – Le nom de la base Cosmos DB dans laquelle rajouter le container. – Id unique du container – Partition key : utilisée pour partitionner automatiquement les données sur les différents serveurs pour la scalabilité. Il faudra bien la choisir. On répartit les documents en suivant la clé de partition sur les partitions logiques, sachant qu’une ou plusieurs partitions logiques sont stockées dans une partition physique. Débit en RU/s (Request Units per seconde). Stockage nécessaire. Limité à 10 Go pour les collections non partitionnées, illimité pour celles partitionnées. |
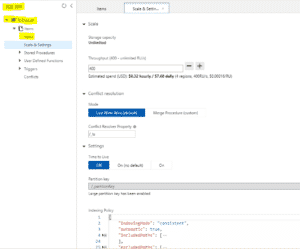 | Une fois le container créé, je peux modifier ses propriétés comme augmenter le nombre de RUs à l’infini, configurer Time To Live, … |
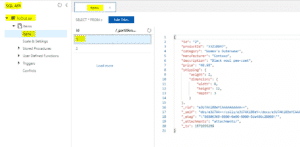 | Si je souhaite voir les documents stockés dans le container, il suffit d’aller sur le container lui-même et cliquer sur une ligne d’Items. Il est possible d’écrire des requêtes qui renvoient des résultats. Pour injecter les données dans Cosmos DB, on peut utiliser : Azure Data Factory, Azure Databricks. |
 | Dans la base Cosmos DB, je peux aussi créer des procédures stockées, des fonctions user et des triggers pour personnaliser les actions et traitements dans ma base Cosmos DB. |
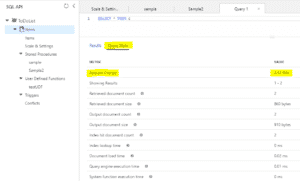 | On peut écrire des requêtes pour consulter les données dans le container et surtout on peut voir les statistiques d’exécution de ces requêtes afin de savoir quelles requêtes optimiser (celles qui consomment le plus de RU). En optimisant les requêtes, on réduit le nombre de RU utilisées et donc le coût total. |
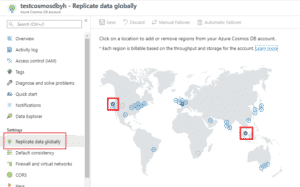 | Rajouter une région de réplication : il suffit de sélectionner l’option « Replicate Data Globally » depuis la base Cosmos DB et simplement cliquer sur les régions dans lesquelles on souhaite répliquer nos données. |
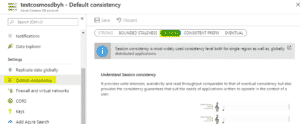 | Ne pas oublier de choisir la consistance de la base. Prendre en compte que le fait d’utiliser « STRONG » ou « BOUNDED STALENESS » utilise deux fois plus de RU/s. « SESSION » est la consistance par défaut. |
 | Je peux également configurer le Failover manuel ou automatique sur une réplication en particulier. Comme mon application se connecte à des Endpoints logiques, il n’y a rien à changer quand il y a des Failover automatiques. |
10- Conclusion
Azure Cosmos DB est une base distribuée importante pour Microsoft, elle permet cinq niveaux de consistances des données, elle est multi-modèles et supporte plusieurs APIs, elle est indexée automatiquement et optimisée pour une latence minimale (garantie de lecture < 10 ms et d’écriture < 15 ms), elle est scalable en stockage et/ou en débit, fournit un émulateur (Azure Cosmos DB Emulator) pour tester les applications utilisant Cosmos DB au moment du développement.
