Je vais vous présenter un package Oracle méconnu dont j’utilise régulièrement les procédures pour reconstruire rapidement en parallèle un grand nombre d’ index en particulier partitionnés.
Le package DBMS_INDEX_UTL est composé de 6 procédures qui permettent de reconstruire les index selon les critères spécifiés en entrée.
Ce package n’est que peu documenté mis à part dans la description incluse dans le code du package, le fichier $ORACLE_HOME/rdbms/admin/dbmsidxu.sql.
Les six procédures sont les suivantes, elles permettent de répondre à la plupart des besoins :
- BUILD_SCHEMA_INDEXES : rebuild de tous les index des schémas indiqués
- BUILD_TABLE_INDEXES : rebuild des index de tables indiquées
- BUILD_INDEXES : rebuild des index donnés en liste
- BUILD_INDEX_COMPONENTS : rebuild des partitions / sous-partitions des index indiqués
- BUILD_TABLE_COMPONENT_INDEXES : rebuild des index des partitions / sous-partitions de tables indiquées
- MULTI_LEVEL_BUILD : procédure reprenant toutes les possibilités combinées des autres
La note MOS How Parallel Execution Differs Between CREATE INDEX and DBMS_INDEX_UTL (Doc ID 959905.1) , que je vous recommande vivement de lire, explique précisément le fonctionnement des procédures au niveau de la gestion du parallélisme.
Les paramètres principaux sont :
- list : Liste de schémas
- Liste de tables (schema.table)
- Liste d’index (schema.index)
- Liste de partitions / sous-partitions (schema.objet)
- locality : type d’index ( LOCAL ou ALL)
- just_unusable : Etat des index : UNUSABLE ou tous
Auquels s’ajoutent les arguments contrôlant le niveau de parallélisme :
- concurrent
- max_slaves
- forced_degree
Je vous recommande de ne jouer que sur le paramètre « max_slaves » (null = degré maximum) pour contrôler le niveau de parallélisme. J’ai en effet obtenu une charge serveur trop importante en tentant d’utiliser le paramètre « force_degree » qui dicte, lui, le parallélisme au niveau session.
En spécifiant un degré de parallélisme adéquat via max_slaves, un nombre correspondant de jobs de rebuild, concurrents ou non, sera lancé par la procédure.
Le paramètre « job_queue_processes » doit donc avoir une valeur au moins supérieure à celui de « max_slaves » (1000 par défaut en 11gR2).
Comme le décrit la note MOS citée plus haut, le parallélisme des rebuilds d’index dépend de la volumétrie de chaque segment (partition ou sous-partition) et détermine si le segment doit être placé dans un « bucket » de rebuild de type parallèle ou série.
Les gros segments sont placés dans le bucket parallèle qui est exécuté en premier, les plus petits sont placés dans un bucket dit « série ».
Pour les segments du bucket parallèle, chaque segment sera reconstruit en intra-parallélisme avec des ordres SQL de la forme :
ALTER INDEX I rebuild partition P parallel;
Les ordres rebuild de ce bucket parallèle sont exécutés l’un après l’autre jusqu’au dernier.
Une fois tous les ordres exécutés, ceux des segments du bucket « série », c’est à dire les segments plus petits, sont exécutés simultanément en parallèle jusqu’à un degré maximum égal au paramètre max_slaves.
ALTER INDEX I rebuild partition P;
Le package comporte quelques autres éléments que je vous laisse explorer, ils permettent entre autres de gérer le comportement en cas d’échec et le code retour.
J’utilise régulièrement ces procédures pour reconstruire facilement les indexes d’une table partitionnée après son rechargement, surtout lorsqu’il y en a beaucoup :
- Truncate de la table
- Désactivation des contraintes
- ALTER INDEX UNUSABLE pour tous les index
- Rechargement de la table (datapump ou autre)
- Reconstruction en parallèle des index par DBMS_INDEX_UTL.BUILD_TABLE_INDEXES()
- Réactivation des contraintes sans validation
- Revalidation en parallèle des contraintes
Concrètement voici un exemple d’exécution sur une table partitionnée par intervalle comportant 500 partitions et 22 index locaux. Les index locaux et de statut « unusable » sont reconstruits avec un parallélisme de 8 jobs concurrents.
exec sys.dbms_index_utl.BUILD_TABLE_INDEXES(list=>'MONSCHEMA.MA_TABLE',concurrent=>TRUE,
locality=>'LOCAL',just_unusable=>TRUE,max_slaves=>8);
Les partitions d’index (plus de 10000) sont reconstruites en environ 10 mn comme le montre la capture d’activité ci-dessous.
Bien qu’identifiés dans la console comme des « CREATE INDEX » il s’agit bien d’ordres « ALTER INDEX ».
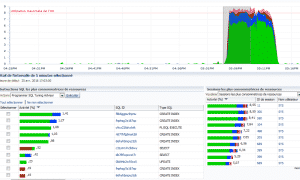
L’intérêt de ces procédures est aussi qu’il n’y a pas besoin d’indiquer les noms des partitions d’index à reconstruire, le nom de la table suffit.
Enfin, pour information, il faut noter l’existence de quelques bugs (corrigés en 11.2.0.4) liés indirectement à l’usage de ces procédures, le refresh de vue matérialisées ferait ainsi appel en interne à ce package :
- ORA-2097 & ORA-1031 When Refreshing a Materialized View in Non-Atomic Mode (Doc ID 1442725.1)
- Mview Refresh Slow Because of SELECT TO_NUMBER(VALUE) FROM V$SES_OPTIMIZER_ENV WHERE NAME = ‘parallel_ddl_forced_degree’ (Doc ID 1484133.1)
