Il ne faut confondre Range Partitioning multi-colonnes et Range-Range Partitioning. Outre la syntaxe, le modèle de partitionnement est très différent. Vous pourrez, dans certains cas, avoir le choix entre l’une et l’autre des implémentations mais ce n’est pas parce qu’on peut utiliser des clous et de la colle pour accrocher un tableau au mur que c’est la même chose…
Cet article présente ces 2 exemples de partitioning Range. Dans un premier temps, ils semblent identiques mais à y regarder de plus prêt et avec à l’aide d’un graphique, vous découvrirez qu’ils sont très différents
Exemple de partitionnement très discret
Pour commencer, vous allez créer 2 tables partitionnées ; la première utilise un partitioning Range-Range alors que la seconde utilise du partitioning range multi-colonne ; exception faîte de la syntaxe, l’exemple semble permettre de gérer de manière identique le jeux de 4 clés mises en oeuvre :
drop table t1 purge;
create table T1(col1 number,
col2 number,
col3 varchar2(1000))
partition by range(col1)
subpartition by range (col2)
subpartition template
(subpartition p0 values less than (1),
subpartition p1 values less than (2))
(partition s0 values less than (1),
partition s1 values less than (2));
insert into t1(col1, col2) values (0,0);
insert into t1(col1, col2) values (1,1);
insert into t1(col1, col2) values (0,1);
insert into t1(col1, col2) values (1,0);
commit;
set serveroutput on
declare
sqltext varchar2(4000);
rval number;
begin
for i in (select subpartition_name
from user_tab_subpartitions
where table_name='T1'
order by subpartition_position) loop
sqltext:='select count(*) from T1 subpartition('||i.subpartition_name||')';
execute immediate sqltext into rval;
dbms_output.put_line('T1('||i.subpartition_name||'): '||to_char(rval));
end loop;
end;
/
T1(S1_P0): 1
T1(S0_P0): 1
T1(S1_P1): 1
T1(S0_P1): 1
drop table t2 purge;
create table T2(col1 number,
col2 number,
col3 varchar2(1000))
partition by range(col1, col2)
(partition p0_s0 values less than (0,1));
alter table t2 add partition p0_s1 values less than (0,2);
alter table t2 add partition p1_s0 values less than (1,1);
alter table t2 add partition p1_s1 values less than (1,2);
insert into t2(col1, col2) values (0,1);
insert into t2(col1, col2) values (0,0);
insert into t2(col1, col2) values (1,0);
insert into t2(col1, col2) values (1,1);
commit;
set serveroutput on
declare
sqltext varchar2(4000);
rval number;
begin
for i in (select partition_name
from user_tab_partitions
where table_name='T2'
order by partition_position) loop
sqltext:='select count(*) from T2 partition('||i.partition_name||')';
execute immediate sqltext into rval;
dbms_output.put_line('T2('||i.partition_name||'): '||to_char(rval));
end loop;
end;
/
T2(P0_S0): 1
T2(P0_S1): 1
T2(P1_S0): 1
T2(P1_S1): 1
Pourquoi ça marche ?
La raison pour laquelle notre exemple semble fonctionner de manière identique tient dans la façon dont on le regarde. En fait, tant qu’on regarde les 2 cas comme sur le graphique ci-dessous, ça fonctionne :
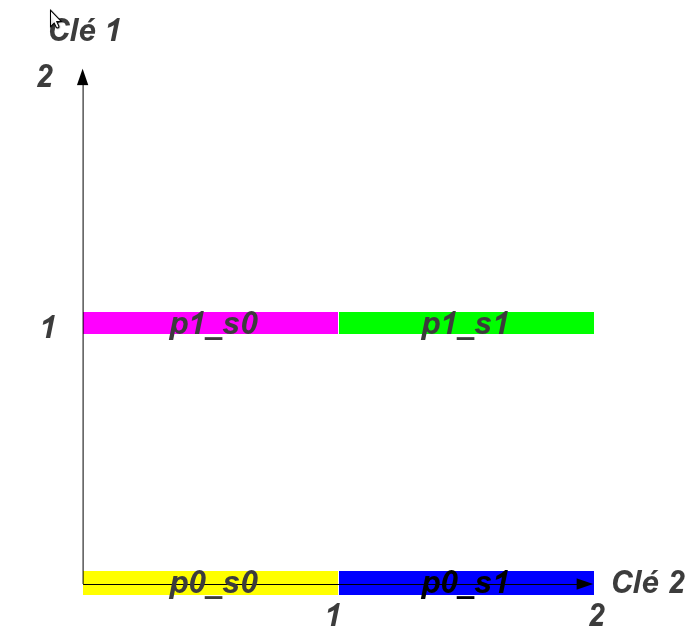
Comment ça marche
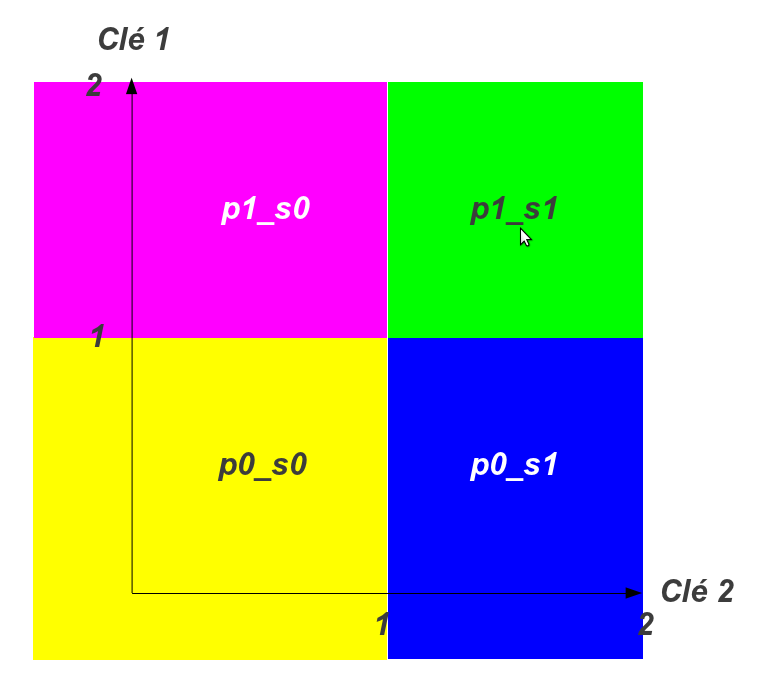
Dans la réalité les 2 modèles de partitioning, comme mentionné en introduction, sont très différents. Dans le cas du partitioning Range-Range, il s’agit bien d’un modèle matriciel comme l’illustre le graphique ci-dessous :
Alors que dans le cas du partitionnement multi-colonnes, il s’agit en fait d’un modèle de partitionnement sur la première clé, sauf sur les bords où c’est la 2nd (puis la 3ème…) clé qui fait fois. Si ce n’est pas évident à comprendre avec des mots, ce n’est pas forcément beaucoup plus claire avec un graphique :

Pour vous en persuader !
Si vous êtes plutôt conceptuel, relisez la documentation et plus particulièrement la section Using Multicolumn Partitioning Keys. Si vous êtes pratique (ou pragmatiques), faîtes quelques tests sur les 2 tables :
insert into T1 values (0.5,0.5,null);
insert into T1 values (0.5,1.5,null);
insert into T1 values (1.5,1.5,null);
insert into T1 values (1.5,0.5,null);
Si vous ré-exécutez le bloc PL/SQL qui analyse la distribution des données dans les partitions, vous voyez que ça fonctionne comme attendu :
T1(S1_P0): 2
T1(S0_P0): 2
T1(S1_P1): 2
T1(S0_P1): 2
Le même exemple dans le cas de la table avec partitionnement multi-colonnes donne des résultats très différents :
insert into T2 values (0.5,0.5,null);
insert into T2 values (0.5,1.5,null);
insert into T2 values (1.5,1.5,null);
*
ERROR at line 1:
ORA-14400: inserted partition key does not map to any partition
insert into T2 values (1.5,0.5,null);
*
ERROR at line 1:
ORA-14400: inserted partition key does not map to any partition
Les nouvelles lignes vont toutes les 2 dans P1_S0 :
T2(P0_S0): 1
T2(P0_S1): 1
T2(P1_S0): 3
T2(P1_S1): 1
Pensez-y… Et quand vous aurez fini, imaginez que votre base de données est une 10g et que la seconde colonne de votre clé de partitionnement multi-colonnes peut être NULL.
