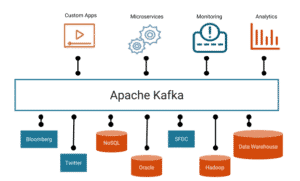
Kafka pour les débutants
Un bref aperçu du contexte Apache Kafka… Tout commence en 2009. En travaillant sur un projet Big Data d’adoption Hadoop ,une équipe de LinkedIn s’est
Un bref aperçu du contexte Apache Kafka… Tout commence en 2009. En travaillant sur un projet Big Data d’adoption Hadoop ,une équipe de LinkedIn s’est

En cette période de pandémie de COVID-19, beaucoup d’espoir se porte sur la recherche, notamment pour le développement d’un vaccin. L’étude du virus passe entre

Nous allons voir dans cet article comment mettre en place un Load Balancer frontal HAProxy pour répartir la charge entre deux serveurs fournissant un service
Problématique Lorsque l’on utilise des diskgroups ASM en environnement Linux, il faut que l’instance puisse identifier les disques qui constituent ses diskgroups de manière invariable.

Vous avez déployé une stack complète dans votre compte AWS, et vous souhaitez ajouter/modifier les tags associés à vos ressources. Prenons l’exemple ci-dessous d’une architecture

Repmgr est un outil open-source développé par 2ndQuadrant permettant d’administrer la réplication de bases de données PostgreSQL. Voyons comment configurer la réplication physique à l’aide

Depuis plusieurs années, le concept de «ville intelligente» a rencontré une grande préoccupation à travers le monde, aujourd’hui, des centaines de projets de ville intelligente

Le backup et la restauration des bases de données PostgreSQL est par défault assez manuel : Le backup consiste à passer la base de données
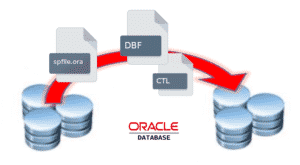
Déplacer les datafiles ou autres fichiers d’une base vers un autre diskgroup n’est pas toujours aisé. Voici une méthode permettant de déplacer n’importe quel type

Vous avez besoin de faire de l’intégration de données dans votre Système d’Informations ? Vous cherchez un ETL pour faire de l’Extraction, de la Transformation